Every time we fail another release, it's a fuss. Guilty people immediately appear, and often it’s us, the testers. Perhaps this is fate - to be the last link in life cycle software, so even if a developer spends a lot of time writing code, then no one even thinks that testing is also people with certain capabilities.
You can’t jump above your head, but you can work 10-12 hours a day. I heard such phrases very often)))
When testing does not meet the needs of the business, then the question arises, why test at all if they do not have time to work on time. Nobody thinks about what happened before, why the requirements were not written properly, why the architecture was not thought out, why the code was crooked. But when you have a deadline, and you do not have time to complete testing, then they immediately begin to punish you ...
But it was a few words about the difficult life of a tester. Now to the point 🙂
After a couple of such fakups, everyone starts to wonder what is wrong in our testing process. Perhaps you, as a leader, you understand the problems, but how do you convey them to management? Question?
Management needs numbers, statistics. Simple words- they listened to you, nodded their heads, said - "Come on, do it" and that's it. After that, everyone expects a miracle from you, but even if you did something and it didn’t work out for you, you or your leader again gets a hat.
Any change must be supported by management, and for management to support it, they need numbers, measurements, statistics.
Many times I saw how they tried to upload various statistics from task trackers, saying that “We remove metrics from JIRA”. But let's understand what a metric is.
A metric is a technically or procedurally measurable value that characterizes the state of the control object.
Let's see - our team finds 50 defects during acceptance testing. It's a lot? Or little? Do these 50 defects tell you about the state of the control object, in particular, the testing process?
Probably not.
And if you were told that the number of defects found during acceptance testing is 80%, while it should be only 60%. I think it’s immediately clear that there are a lot of defects, respectively, to put it mildly, the developers’ code is completely g ... .. unsatisfactory in terms of quality.
Someone can say that why then testing? But I will say that defects are testing time, and testing time is what directly affects our deadline.
Therefore, we need not just metrics, we need KPIs.
KPI is a metric that serves as an indicator of the state of the control object. A prerequisite is the presence of a target value and established tolerances.
That is, always, when building a system of metrics, you must have a goal and allowable deviations.
For example, you need (your goal) that 90% of all defects are solved from the first iteration. At the same time, you understand that this is not always possible, but even if the number of defects resolved the first time is 70%, this is also good.
That is, you set yourself a goal and an acceptable deviation. Now, if you count the defects in the release and get a value of 86%, then this is certainly not good, but it is no longer a failure.
Mathematically it will look like:
Why 2 formulas? This is due to the fact that there is a concept of ascending and descending metrics, i.e. when our target value approaches 100% or 0%.
Those. if we are talking, for example, about the number of defects found after implementation in commercial operation, then the less the better, and if we are talking about covering the functionality with test cases, then everything will be the other way around.
At the same time, do not forget about how to calculate this or that metric.
In order to get the percentages, pieces, etc. we need, we need to calculate each metric.
For an illustrative example, I will tell you about the metric “Timeliness of defect processing by testing”.
Using a similar approach, which I described above, we also form a KPI for the metric based on the target values and deviations.
Don't worry, it's not as hard in real life as it looks in the picture!

What we have?
Well, it is clear that the release number, the incident number ....
Critical - odds. 5,
Major - odds. 3,
Minor - odds. 1.5.
Next, you need to specify the SLA for the defect processing time. To do this, the target value and the maximum allowable retest time are determined, similar to how I described it above for calculating metrics.
To answer these questions, we'll jump straight to the performance metric and ask the question straight away. And how to calculate the indicator if the value of one request can be equal to “zero”. If one or more indicators is equal to zero, then the final indicator will decrease very much, so the question arises how to balance our calculation so that zero values, for example, of requests with a severity factor of “1”, do not greatly affect our final assessment.
The weight is the value we need in order to have the least impact of requests on the final score with a low severity, and vice versa, a request with the highest severity has a serious impact on the score, provided that we are overdue on this request.
In order for you not to have misunderstanding in the calculations, we will introduce specific variables for the calculation:
x is the actual time spent retesting the defect;
y is the maximum allowable deviation;
z is the gravity factor.

Or in common language, this is:
W=ESLI(x<=y,1,(x/y)^z)
Thus, even if we went beyond our SLA limits, our request, depending on the severity, will not seriously affect our final score.
All as described above:
X– actual time spent retesting the defect;
y– the maximum allowable deviation;
z is the gravity factor.
h- planned time according to SLA
I no longer know how to express this in a mathematical formula, so I will write in a programming language with the operator IF.
R = IF(x<=h;1;ЕСЛИ(x<=y;(1/z)/(x/y);0))
As a result, we get that if we reached the goal, then our request value is equal to 1, if we went beyond the permissible deviation, then the rating is equal to zero and the weights are calculated.
If our value is between the target and the maximum allowable deviation, then depending on the severity factor, our value varies in the range .
Now I will give a couple of examples of how it will look in our metrics system.
Each request has its own SLA depending on their importance (severity factor).
What do we see here.
In the first request, we only deviated from our target value by an hour and already have a rating of 30%, while in the second request we also deviated by only one hour, but the sum of the indicators is no longer 30%, but 42.86%. That is, the severity coefficients play an important role in the formation of the final indicator of the request.
At the same time, in the third request, we violated the maximum allowable time and the rating is equal to zero, but the weight of the request has changed, which allows us to more correctly calculate the impact of this request on the final coefficient.
Well, to make sure of this, you can simply calculate that the arithmetic mean of the indicators will be 43.21%, and we got 33.49%, which indicates a serious impact of requests with high importance.
Let's change the values in the system to 1 hour.

at the same time, for the 5th priority, the value changed by 6%, and for the third - by 5.36%.
Again, the importance of a query affects its score.
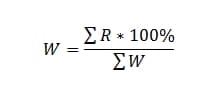
That's it, we get the final indicator of the metric.
What's important!
I'm not saying that the use of the metrics system should be done by analogy with my values, I'm just suggesting an approach to maintaining and collecting them.
In one organization, I saw that they developed their own framework for collecting metrics from HP ALM and JIRA. It's really cool. But it is important to remember that such a process of maintaining metrics requires serious adherence to regulatory processes.
Well, and most importantly, only you can decide how and what metrics you collect. You don't need to copy those metrics that you can't collect.
The approach is complex but effective.
Try it and maybe you can too!
Alexander Meshkov, Chief Operations Officer at Performance Lab, has over 5 years of experience in software testing, test management and QA consulting. Expert ISTQB, TPI, TMMI.
Software testing is the evaluation of the software/product being developed to check its capabilities, capabilities and conformity with the expected results. There are different types of methods used in the field of testing and quality assurance and will be discussed in this article.
Software testing is an integral part of the software development cycle.
What is software testing?
Software testing is nothing more than testing a piece of code to controlled and uncontrolled operating conditions, observing the output, and then examining whether it meets predefined conditions.
Various sets of test cases and testing strategies are aimed at achieving one common goal - eliminating bugs and errors in the code, and ensuring accurate and optimal software performance.
Test Methodology
The commonly used testing methods are unit testing, integration testing, acceptance testing, and system testing. The software is subjected to these tests in a specific order.
3) System testing
4) Acceptance tests
The first step is a unit test. As the name suggests, this is an object-level test method. Individual software components are tested for errors. This test requires precise knowledge of the program and each installed module. Thus, this verification is done by programmers, not testers. To do this, test codes are created that check whether the software behaves as intended.

Individual modules that have already been unit tested are integrated with each other and checked for faults. This type of testing primarily identifies interface errors. Integration testing can be done using a top-down approach, following the architectural design of the system. Another approach is the bottom-up approach, which is done from the bottom of the control flow.
System testing
In this testing, the entire system is checked for errors and bugs. This test is carried out by interfacing the hardware and software components of the entire system, and then it is tested. This testing is listed under the "black box" testing method, where the expected operating conditions for the user of the software are checked.
Acceptance tests
This is the last test that is carried out before handing over the software to the client. It is carried out to ensure that the software that has been developed meets all customer requirements. There are two types of acceptance testing - one that is carried out by members of the development team is known as internal acceptance testing (Alpha testing), and the other that is conducted by the customer is known as external acceptance testing.
When testing is done with the help of prospective customers, it is called customer acceptance testing. When testing is performed by the end user of the software, it is known as acceptance testing (beta testing).
There are several basic testing methods that form part of the software testing regimen. These tests are usually considered self-sufficient in finding errors and bugs throughout the system.
Black box testing
Black box testing is done without any knowledge of the internal workings of the system. The tester will incentivize the user environment software by providing various inputs and testing the generated outputs. This test is also known as black-box, closed-box testing or functional testing.
White box testing
White box testing, unlike black box testing, takes into account the internal functioning and logic of the code. To perform this test, the tester must have code knowledge to know the exact part of the code that has errors. This test is also known as White-box, Open-Box or Glass box testing.
Gray box testing
Gray box testing, or Gray box testing, is a cross between White Box and Black Box testing, where the tester only has the general knowledge of the product needed to complete the test. This verification is done through documentation and information flow diagram. Testing is conducted by the end user, or users who appear to be end users.
Non-functional tests

Application security is one of the main tasks of the developer. Security testing checks software for confidentiality, integrity, authentication, availability, and non-repudiation. Individual tests are carried out in order to prevent unauthorized access to the program code.

Stress testing is a technique in which software is exposed to conditions that are outside the normal operating conditions of the software. After reaching the critical point, the results are recorded. This test determines the stability of the entire system.

The software is tested for compatibility with external interfaces such as operating systems, hardware platforms, web browsers, etc. The compatibility test checks if the product is compatible with any software platform.

As the name suggests, this testing technique tests the amount of code or resources used by a program to perform a single operation.

This testing tests the aspect of user friendliness and usability of the software. The ease with which a user can access a device forms the main point of testing. Usability testing covers five aspects of testing - learnability, performance, satisfaction, memorability, and errors.
Tests in the software development process

The waterfall model uses a top-down approach, whether it is used for software development or testing.
The main steps involved in this software testing methodology are:
- Needs Analysis
- Design test
- Implementation Test
- Testing, debugging and verifying code or product
- Implementation and maintenance
In this technique, you only move to the next step after you have completed the previous one. The model uses a non-iterative approach. The main advantage of this methodology is its simplified, systematic and orthodox approach. However, it has many drawbacks, as bugs and bugs in the code will not be discovered until the testing phase. This can often result in wasted time, money, and other valuable resources.
Agile Model
This methodology is based on a selective combination of a sequential and iterative approach, in addition to a fairly large variety of new development methods. Rapid and progressive development is one of the key principles of this methodology. The emphasis is on getting quick, practical, and visible outputs. Continuous customer interaction and participation is an integral part of the entire development process.
Rapid Application Development (RAD). Rapid Application Development Methodology
The name speaks for itself. In this case, the methodology takes a rapid evolutionary approach, using the principle of component construction. After understanding the various requirements of a given project, a rapid prototype is prepared and then compared to the expected set of output conditions and standards. Necessary changes and modifications are made after a joint discussion with the customer or development team (in the context of software testing).
While this approach has its share of advantages, it may not be appropriate if the project is large, complex, or extremely dynamic in nature, in which requirements are constantly changing.
spiral model
As the name implies, the spiral model is based on an approach where there are a number of cycles (or spirals) from all successive steps in the waterfall model. After the initial cycle is completed, a thorough analysis and review of the achieved product or output is carried out. If the output does not meet specified requirements or expected standards, a second cycle is performed, and so on.
Rational Unified Process (RUP). Rational Unified Process
The RUP methodology is also similar to the spiral model, in the sense that the entire testing procedure is divided into several cycles. Each cycle consists of four stages - creation, development, construction, and transition. At the end of each cycle, the product/yield is reviewed and a further cycle (consisting of the same four phases) follows as needed.
The use of information technology is growing every day, and the importance of proper software testing has grown significantly. Many firms maintain a staff of special teams for this, the capabilities of which are at the level of developers.
When needed: to assess the relationship in the team, the interest of employees in obtaining results and their motivation.
Woodcock test
Instruction
Read the statements that describe your team and circle the numbers of those you agree with. If you think that the statement is not entirely true, then leave the answer field blank.
Don't spend a lot of time thinking about each statement: a few seconds is enough.
Remember that the results will only make sense if you are sincere.
Test
1. Our team excels in leadership.
2. Decisions seem to be forced on us.
3. People are not encouraged to speak out.
4. In a difficult situation, everyone takes up their interests.
5. Communication needs improvement.
6. Decisions are made at an inadequate level of hierarchy.
7. Some managers are not sincere with themselves.
8. We rarely question the substance or usefulness of our meetings.
9. Insufficient development opportunities created.
10. We often quarrel with other divisions.
11. Team members don't communicate well with each other.
12. It is clear what the organization expects from our team.
13. The accepted order is rarely questioned.
14. In reality, it is not clear to anyone where we are going.
15. People don't say what they really think.
16. People have the position "my hut is on the edge."
17. In a team, conflict is destructive.
18. Decisions are based on inadequate information.
19. Some managers are not trusted.
20. We don't learn from our mistakes.
21. Managers don't help their subordinates learn.
22. Relations with other groups are cool.
23. We do not think well about our position within the organization.
24. Our team is "politically" receptive.
25. We often find ourselves lacking the right qualifications.
26. We are all very busy, but it seems that we do not have time for everything.
27. Controversial issues hide under the rug.
28. It would help if people were more willing to admit their mistakes.
29. There is distrust and hostility.
30. People are not allowed to make decisions.
31. Little loyalty to the team.
32. Opinions from outside are not welcome.
33. Should have a large rotation of work.
34. We rarely work effectively with other teams.
35. We failed to ensure cooperation with other teams and units.
36. The ability to work in a team is a selection criterion for admission to this organization.
37. No one is making the necessary connections with other groups.
38. We don't spend the required time planning for the future.
39. Delicate questions are avoided.
40. It happens that someone has been "stabbed in the back."
41. We don't really work together.
42. Wrong people make decisions.
43. Managers are weak and not ready to fight and demand attention to their point of view.
44. I don't get enough feedback.
45. Inappropriate types of skills are developed.
46. Help will not come from other parts of the organization.
47. There is a strong misunderstanding between our team and the trade unions that put pressure on us.
48. Teamwork is rewarded in this organization.
49. We don't pay enough attention to relationships.
50. We do not have a clear idea of what is expected of us.
51. Honesty is not a characteristic feature of our team.
52. I do not feel support from my colleagues.
53. Skills and information are not well distributed.
54. There are strong personalities who go their own way.
55. Self-respect is frowned upon.
56. We should spend more time discussing working methods.
57. Managers don't take personal development seriously.
58. Other parts of the organization do not understand us.
59. We fail to get our message across to the outside world.
60. People on the team have good connections with other members of the organization.
61. Often we reach decisions too quickly.
62. A course of action that values the individual has little to do with what has been achieved.
63. Too many secrets.
64. Conflict is avoided.
65. Disagreements corrupt.
66. Commitment to solutions is low.
67. Our managers believe that greater oversight improves outcomes.
68. Too many bans in our team.
69. It is clear that there are better opportunities in another unit.
70. We spend a lot of energy protecting our borders.
71. Team members do not understand what is expected of them.
72. The culture of the organization encourages teamwork.
73. We don't pay enough attention to new ideas.
74. Priorities are not clear.
75. People are not sufficiently involved in decision making.
76. Too many mutual accusations and reproaches.
77. They don't always listen.
78. We do not make full use of the skills we have.
79. Managers believe that people are inherently lazy.
80. We spend a lot of time doing and don't spend enough time thinking.
81. The desire of the individual to grow is not encouraged.
82. We do not try to understand the point of view of other teams.
83. We fail to listen to our clients.
84. The team works in accordance with the goals of the organization.
Thanks for answers!
The Key to the Woodcock Test for Evaluating Team Performance
Description
The Woodcock test is designed to measure team performance. Allows you to evaluate the relationship in the team, the interest of employees in obtaining results and their motivation. The loyalty of the company and the level of interaction between departments of the organization are also taken into account.
The principle of testing is simple. Each team member, regardless of position, completes a questionnaire that includes 84 statements. Then, according to a special table, the results are calculated and analyzed.
If you doubt that team members will honestly answer questions, try to ensure the anonymity of testing. By and large, this is already an indicator of the relationship in the team. Nevertheless, it is still useful to conduct testing, since its results allow you to more accurately identify shortcomings in the work of the team.
In addition, it is very useful to compare the test results of managers and their subordinates. This allows you to assess the atmosphere in the team and determine the degree of trust of subordinates to the leadership.
Key to the test
Transfer the highlighted answers from the questionnaire to the result table. Count the number of marks in each column. Write the quantity in the "Total" line.
Result table
| BUT | AT | FROM | D | E | F | G | H | I | J | To | L | |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | |
| 37 | 38 | 39 | 40 | 41 | 42 | 43 | 44 | 45 | 46 | 47 | 48 | |
| 49 | 50 | 51 | 52 | 53 | 54 | 55 | 56 | 57 | 58 | 59 | 60 | |
| 61 | 62 | 63 | 64 | 65 | 66 | 67 | 68 | 69 | 70 | 71 | 72 | |
| 73 | 74 | 75 | 76 | 77 | 78 | 79 | 70 | 81 | 82 | 83 | 84 | |
| Total |
Transfer the column count from the "Total" row to the table.
In recent years, automated testing has become a trend in the field of software development, in a sense, its implementation has become a "feed to fashion". However, the implementation and support of automated tests is a very resource-intensive and, accordingly, expensive procedure. The widespread use of this tool most often leads to significant financial losses without any significant result.
How can you use a fairly simple tool to evaluate the possible effectiveness of using autotests on a project?
What is defined as "efficiency" of test automation?
The most common way to evaluate efficiency (primarily economic) is return on investment calculation(ROI). It is calculated quite simply, being the ratio of profit to costs. As soon as the ROI value passes one, the solution returns the funds invested in it and begins to bring new ones.
In the case of automation, profit means savings on manual testing. In addition, the profit in this case may not be obvious - for example, the results of finding defects in the process of ad-hoc testing by engineers, whose time was freed up due to automation. Such a profit is quite difficult to calculate, so you can either make an assumption (for example, + 10%) or omit it.
However, saving is not always the goal of implementing automation. One example is test execution speed(both in terms of the speed of performing one test, and in terms of the frequency of testing). For a number of reasons, the speed of testing can be critical for a business - if investments in automation pay off with the received profit.
Another example - exclusion of the "human factor" from the system testing process. This is important when the accuracy and correctness of the execution of operations is critical for the business. The price of such an error can be much higher than the cost of developing and maintaining an autotest.
Why measure performance?
Efficiency measurement helps answer the questions: “Is it worth implementing automation on a project?”, “When will the implementation bring us a significant result?”, “How many hours of manual testing will we replace?”, “Is it possible to replace 3 manual testing engineers with 1 automated testing engineer ? and etc.
These calculations can help formulate goals (or metrics) for the automated testing team. For example, saving X hours per month of manual testing, reducing the cost of the testing team by Y units.







How to disable ads on Android: remove pop-up ads
The Russian received a term and a million fine for "piracy Negative consequences of the law
Identification of key factors
The criteria for classifying organizations and individual entrepreneurs as small and medium-sized businesses have changed
See what "Royalty" is in other dictionaries Pitfalls of legislation