CONCLUSION DES RÉSULTATS
| Statistiques de régression | |
| Pluriel R | 0,998364 |
| R Carré | 0,99673 |
| R carré normalisé | 0,996321 |
| Erreur standard | 0,42405 |
| Observations | 10 |
Examinons d’abord la partie supérieure des calculs, présentée dans le tableau 8.3a – les statistiques de régression.
La valeur R au carré, également appelée mesure de certitude, caractérise la qualité de la droite de régression résultante. Cette qualité s'exprime par le degré de correspondance entre les données sources et le modèle de régression (données calculées). La mesure de la certitude se situe toujours dans l'intervalle.
Dans la plupart des cas, la valeur R au carré se situe entre ces valeurs, appelées valeurs extrêmes, c'est-à-dire entre zéro et un.
Si la valeur R au carré est proche de un, cela signifie que le modèle construit explique presque toute la variabilité des variables pertinentes. À l’inverse, une valeur R au carré proche de zéro signifie que la qualité du modèle construit est médiocre.
Dans notre exemple, la mesure de certitude est de 0,99673, ce qui indique un très bon ajustement de la droite de régression aux données d'origine.
Pluriel R- coefficient de corrélation multiple R - exprime le degré de dépendance des variables indépendantes (X) et de la variable dépendante (Y).
Le multiple R est égal à la racine carrée du coefficient de détermination ; cette quantité prend des valeurs comprises entre zéro et un.
Dans une analyse de régression linéaire simple, le multiple R est égal au coefficient de corrélation de Pearson. En effet, le multiple R dans notre cas est égal au coefficient de corrélation de Pearson de l'exemple précédent (0,998364).
| Chances | Erreur standard | statistique t | |
| Intersection en Y | 2,694545455 | 0,33176878 | 8,121757129 |
| Variable X 1 | 2,305454545 | 0,04668634 | 49,38177965 |
| * Une version tronquée des calculs est fournie | |||
Considérons maintenant la partie médiane des calculs, présentée dans le tableau 8.3b. Ici, le coefficient de régression b (2,305454545) et le déplacement le long de l'axe des ordonnées sont donnés, c'est-à-dire constante une (2,694545455).
Sur la base des calculs, nous pouvons écrire l’équation de régression comme suit :
Oui= x*2,305454545+2,694545455
Le sens de la relation entre les variables est déterminé en fonction des signes (négatifs ou positifs) coefficients de régression(coefficient b).
Si le signe à Coefficient de régression- positif, la relation entre la variable dépendante et la variable indépendante sera positive. Dans notre cas, le signe du coefficient de régression est positif, donc la relation est également positive.
Si le signe à Coefficient de régression- négatif, la relation entre la variable dépendante et la variable indépendante est négative (inverse).
Dans le tableau 8.3c. Les résultats du calcul des résidus sont présentés. Pour que ces résultats apparaissent dans le rapport, vous devez cocher la case « Résidus » lors de l'exécution de l'outil « Régression ».
RETRAIT DU RESTE
| Observation | Y prédit | les restes | Balances standards |
|---|---|---|---|
| 1 | 9,610909091 | -0,610909091 | -1,528044662 |
| 2 | 7,305454545 | -0,305454545 | -0,764022331 |
| 3 | 11,91636364 | 0,083636364 | 0,209196591 |
| 4 | 14,22181818 | 0,778181818 | 1,946437843 |
| 5 | 16,52727273 | 0,472727273 | 1,182415512 |
| 6 | 18,83272727 | 0,167272727 | 0,418393181 |
| 7 | 21,13818182 | -0,138181818 | -0,34562915 |
| 8 | 23,44363636 | -0,043636364 | -0,109146047 |
| 9 | 25,74909091 | -0,149090909 | -0,372915662 |
| 10 | 28,05454545 | -0,254545455 | -0,636685276 |
En utilisant cette partie du rapport, nous pouvons voir les écarts de chaque point par rapport à la droite de régression construite. Plus grande valeur absolue
Ce chapitre poursuit le thème du chapitre Construction et analyse des tableaux. Nous vous recommandons de le réviser puis de commencer la lecture de ce texte et des exercices STATISTICA.
L'analyse des correspondances (en anglais coirespondence Analysis) est une méthode d'analyse exploratoire qui permet d'examiner visuellement et numériquement la structure de tableaux de contingence de grande dimension.
Actuellement, l'analyse des correspondances est intensivement utilisée dans divers domaines, notamment en sociologie, économie, marketing, médecine, gestion urbaine (voir par exemple Thomas Werani, Correspondence Analysis as a Means for Developing City Marketing Strategies, 3rd International Conference on recent Advances in Retailing and Services Science, pp. 22-25, juin 1996, Telfs-Buchen (Osterreich) Werani, Thomas).
Il existe des applications connues de la méthode en archéologie, en analyse de texte, où il est important d'examiner les structures de données (voir Greenacre, M. J., 1993, Correspondence Analysis in Practice, Londres : Academic Press).
Voici quelques exemples supplémentaires :
- Etude des groupes sociaux de la population dans diverses régions avec des postes de dépenses pour chaque groupe.
- Les études des résultats des votes à l'ONU sur des questions fondamentales (1 - pour, 0 - contre, 0,5 - abstention, par exemple, en 1967, 127 pays ont été étudiés sur 13 questions importantes) montrent que selon le premier facteur, les pays sont clairement divisé en deux groupes : l'un avec le centre des USA, l'autre avec le centre de l'URSS (modèle bipolaire du monde). D’autres facteurs peuvent être interprétés comme l’isolationnisme, l’absence de vote, etc.
- Recherche sur les importations de voitures (marque de voiture - ligne du tableau, pays de fabrication - colonne).
- Etude des tableaux utilisés en paléontologie, lorsque, à partir d'un échantillon de parties éparses de squelettes d'animaux, on tente de les classer (les attribuer à l'un des types possibles : zèbre, cheval, etc.).
- Recherche de textes. L'exemple exotique suivant est connu : le magazine New-Yorkais a demandé à des linguistes d'identifier l'auteur anonyme d'un livre scandaleux sur une campagne présidentielle. Les experts se sont vu proposer des textes de 15 auteurs possibles ainsi que le texte d'une publication anonyme. Les textes étaient représentés par des lignes de tableau. Ligne i a noté la fréquence d'un mot donné j. Ainsi, un tableau de contingence a été obtenu. L'auteur le plus probable du texte scandaleux a été déterminé à l'aide de la méthode d'analyse des correspondances.
L'utilisation de l'analyse des correspondances en médecine est associée à l'étude de la structure de tableaux complexes contenant des variables indicatrices montrant la présence ou l'absence d'un symptôme donné chez un patient. Les tableaux de ce type ont une grande dimension et étudier leur structure est une tâche non triviale.
Les problèmes de visualisation d'objets complexes peuvent également être étudiés, ou du moins une approche peut être trouvée, utilisant l'analyse des correspondances. Une image est un tableau multidimensionnel et la tâche consiste à trouver un plan qui permet de reproduire l'image originale aussi précisément que possible.
Base mathématique de la méthode. L'analyse des correspondances repose sur la statistique du chi carré. On peut dire qu’il s’agit d’une nouvelle interprétation de la statistique du chi carré de Pearson.
La méthode est à bien des égards similaire à l'analyse factorielle, cependant, contrairement à elle, les tableaux de contingence sont étudiés ici, et le critère de qualité de reproduction d'un tableau multidimensionnel dans un espace de dimension inférieure est la valeur de la statistique du chi carré. De manière informelle, nous pouvons parler de l'analyse des correspondances comme d'une analyse factorielle de données catégorielles et la considérer également comme une méthode de réduction de dimensionnalité.
Ainsi, les lignes ou les colonnes du tableau d'origine sont représentées par des points dans l'espace, entre lesquels la distance du chi carré est calculée (de la même manière que la statistique du chi carré est calculée pour comparer les fréquences observées et attendues).
Ensuite, vous devez trouver un espace de petite dimension, généralement bidimensionnel, dans lequel les distances calculées sont le moins déformées et, en ce sens, reproduire le plus précisément possible la structure du tableau d'origine tout en préservant les relations entre les entités (si vous avez une idée des méthodes de mise à l'échelle multidimensionnelle, vous ressentirez une mélodie familière).
On part donc d'un tableau de contingence régulier, c'est-à-dire un tableau dans lequel plusieurs caractéristiques sont conjuguées (pour plus d'informations sur les tableaux de contingence, voir le chapitre Construction et analyse des tableaux).
Supposons qu'il existe des données sur l'habitude de fumer des employés d'une certaine entreprise. Des données similaires sont disponibles dans le fichier Smoking.sta, qui est inclus dans l'ensemble standard d'exemples du système STATISTICA.
Dans ce tableau, l'attribut fumer est associé à l'attribut position :
|
Groupe d'employés |
(1) Non-fumeurs |
(2) Fumeurs légers |
(3) Fumeurs modérés |
(4) Gros fumeurs |
Total par ligne |
|
(1) Cadres supérieurs |
|||||
|
(2) Cadres juniors |
|||||
|
(3) Employés seniors |
|||||
|
(4) Employés juniors |
|||||
|
(5) Secrétaires |
|||||
|
Total par colonne |
Il s’agit d’un simple tableau de contingence à deux entrées. Regardons d'abord les lignes.
On peut supposer que les 4 premiers nombres de chaque ligne du tableau (fréquences marginales, c'est-à-dire que la dernière colonne n'est pas prise en compte) sont les coordonnées de la ligne dans l'espace à 4 dimensions, ce qui signifie que l'on peut calculer formellement la distances du chi carré entre ces points (lignes du tableau).
Pour ces fréquences marginales, il est possible d'afficher ces points dans un espace de dimension 3 (le nombre de degrés de liberté est de 3).
Évidemment, plus la distance est petite, plus la similitude entre les groupes est grande, et vice versa : plus la distance est grande, plus la différence est grande.
Supposons maintenant que nous puissions trouver un espace de dimension inférieure, disons la dimension 2, pour représenter les points de ligne qui préserve toutes, ou plus précisément presque toutes, les informations sur les différences entre les lignes.
Cette approche n'est peut-être pas efficace pour les petits tableaux comme celui ci-dessus, mais elle est utile pour les grands tableaux comme ceux rencontrés dans les études marketing.
Par exemple, si les préférences de 100 personnes interrogées sont enregistrées lors du choix de 15 types de bière, alors grâce à l'application de l'analyse des correspondances, il est possible de représenter 15 variétés (points) sur un avion (voir ci-dessous pour l'analyse des ventes). En analysant l'emplacement des points, vous verrez des modèles de sélection de bière qui seront utiles dans votre campagne marketing.
Il existe un certain argot utilisé dans l'analyse des correspondances.
Poids. Les observations du tableau sont normalisées : les fréquences relatives du tableau sont calculées, la somme de tous les éléments du tableau devient égale à 1 (chaque élément est divisé par le nombre total d'observations, dans cet exemple par 193). Un analogue d'une densité de distribution bidimensionnelle est créé. Le tableau standardisé qui en résulte montre comment la masse est répartie entre les cellules du tableau ou les points de l'espace. Dans le jargon de l'analyse des correspondances, les sommes de lignes et de colonnes dans une matrice de fréquence relative sont appelées respectivement masses de lignes et de colonnes.
Inertie. L'inertie est définie comme la valeur du chi carré de Pearson pour un tableau à deux entrées divisée par le nombre total d'observations. Dans cet exemple : inertie totale = 2 /193 - 16,442.
Inertie et profils de lignes et de colonnes. Si les lignes et les colonnes d'un tableau sont complètement indépendantes (il n'y a aucune relation entre elles - par exemple, le fait de fumer ne dépend pas de l'intitulé du poste), alors les éléments du tableau peuvent être reproduits à l'aide de sommes de lignes et de colonnes ou, dans le cadre d'une analyse des correspondances. terminologie, en utilisant des profils de lignes et de colonnes (avec utilisation de fréquences marginales ; voir le chapitre Construction et analyse de tableaux pour une description du test du chi carré de Pearson et du test exact de Fisher).
Selon la formule bien connue de calcul du chi carré pour les tableaux à deux entrées, les fréquences attendues d'un tableau dans lequel les colonnes et les lignes sont indépendantes sont calculées en multipliant les profils correspondants des colonnes et des lignes et en divisant le résultat par le total.
Tout écart par rapport aux valeurs attendues (sous l'hypothèse d'une totale indépendance des variables en lignes et en colonnes) contribuera aux statistiques du chi carré.
L'analyse des correspondances peut être considérée comme décomposant la statistique du chi carré en ses composantes pour déterminer le plus petit espace dimensionnel pour représenter les écarts par rapport aux valeurs attendues (voir le tableau ci-dessous).
Voici des tableaux avec les fréquences attendues calculées sous l'hypothèse d'indépendance des caractéristiques et des fréquences observées, ainsi qu'un tableau des contributions des cellules au chi carré :

Par exemple, le tableau montre que le nombre de jeunes employés non-fumeurs est environ 10 de moins que ce à quoi on pourrait s'attendre dans l'hypothèse de l'indépendance. Le nombre de salariés seniors non-fumeurs, au contraire, est 9 de plus que ce à quoi on pourrait s'attendre dans l'hypothèse de l'indépendance, etc. Cependant, j'aimerais avoir une vue d'ensemble.
Le but de l'analyse des correspondances est de résumer ces écarts par rapport aux fréquences attendues, non pas en termes absolus, mais en termes relatifs.

Analyse des lignes et des colonnes. Au lieu de lignes de tableau, on peut également considérer des colonnes et les représenter comme des points dans un espace de dimension inférieure qui reproduit aussi fidèlement que possible les similitudes (et les distances) entre les fréquences relatives des colonnes du tableau. Vous pouvez afficher simultanément des colonnes et des lignes représentant toutes les informations contenues dans un tableau à deux entrées sur un seul graphique. Et cette option est la plus intéressante, car elle permet une analyse significative des résultats.
Résultats. Les résultats de l’analyse des correspondances sont généralement présentés sous forme de graphiques, comme indiqué ci-dessus, ainsi que sous forme de tableaux tels que :
|
Nombre de mesures |
Pourcentage d'inertie |
Pourcentage cumulé |
Chi carré |
Regardez ce tableau. Comme vous vous en souvenez, le but de l'analyse est de trouver un espace de dimension inférieure qui reconstruit le tableau, le critère de qualité étant le chi carré normalisé, ou inertie. On peut noter que si dans l'exemple considéré on utilise un espace unidimensionnel, c'est-à-dire un axe, 87,76% de l'inertie de la table peut être expliquée.

Deux dimensions expliquent 99,51% de l'inertie.
Coordonnées des lignes et des colonnes. Considérons les coordonnées résultantes dans un espace bidimensionnel.
|
Nom de la chaîne |
Changement 1 |
Changement 2 |
|
Cadres supérieurs |
||
|
Cadres juniors |
||
|
Cadres supérieurs |
||
|
Employés juniors |
||
|
Secrétaires |
Vous pouvez représenter cela dans un diagramme en deux dimensions.

Un avantage évident de l’espace bidimensionnel est que les lignes affichées comme points proches sont proches les unes des autres et en fréquences relatives.
En considérant la position des points le long du premier axe, on peut voir que l'Art. Les employés et les secrétaires sont relativement proches en coordonnées. Si vous faites attention aux lignes du tableau des fréquences relatives (les fréquences sont standardisées de manière à ce que leur somme pour chaque ligne soit égale à 100 %), alors la similitude des données des deux groupes dans les catégories d'intensité du tabagisme devient évidente.
Pourcentages de lignes :
| Catégories de fumeurs | |||||
|
Groupe d'employés |
(1) Non-fumeurs |
(2) Fumeurs légers |
(3) Fumeurs modérés |
(4) Gros fumeurs |
Total par ligne |
|
(1) Cadres supérieurs |
|||||
|
(2) Cadres juniors |
|||||
|
(3) Employés seniors |
|||||
|
(4) Employés juniors |
|||||
|
(5) Secrétaires |
|||||
Le but ultime de l’analyse des correspondances est d’interpréter les vecteurs dans l’espace de dimension inférieure résultant. Une façon de vous aider à interpréter vos résultats consiste à les représenter dans un graphique à barres. Le tableau suivant montre les coordonnées des colonnes :
|
Cote 1 |
Cote 2 |
|
|
Non-fumeurs |
||
|
Fumeurs légers |
||
|
Fumeurs modérés |
||
|
Gros fumeurs |
On peut dire que le premier axe donne une gradation de l'intensité du tabagisme. Ainsi, le plus grand degré de similarité entre les cadres supérieurs et les secrétaires peut s'expliquer par la présence d'un grand nombre de non-fumeurs dans ces groupes.
Métrique du système de coordonnées. Dans un certain nombre de cas, le terme distance était utilisé pour désigner les différences entre les lignes et les colonnes d’une matrice de fréquences relatives, qui à leur tour étaient représentées dans un espace de dimension inférieure grâce à l’utilisation de techniques d’analyse des correspondances.
En réalité, les distances représentées sous forme de coordonnées dans un espace de dimension appropriée ne sont pas simplement des distances euclidiennes calculées à partir des fréquences relatives des colonnes et des lignes, mais des distances pondérées.
La procédure de sélection des poids est conçue de telle manière que dans un espace de dimension inférieure, la métrique est la métrique du chi carré, étant donné que les points des lignes sont comparés et que la standardisation des profils de lignes ou la standardisation des profils de lignes et de colonnes est sélectionnée, ou le point -les colonnes sont comparées et la standardisation des profils de colonnes est sélectionnée ou la standardisation des profils de lignes et de colonnes.
Évaluer la qualité de la solution. Il existe des statistiques spéciales qui permettent d'évaluer la qualité de la solution résultante. La totalité ou la plupart des points doivent être correctement représentés, c'est-à-dire que les distances entre eux résultant de l'application de la procédure d'analyse des correspondances ne doivent pas être faussées. Le tableau suivant montre les résultats du calcul des statistiques sur les coordonnées de ligne disponibles basées uniquement sur la solution unidimensionnelle de l'exemple précédent (c'est-à-dire qu'une seule dimension a été utilisée pour reconstruire les profils de ligne de la matrice de fréquence relative).
Coordonnées et contribution à l'inertie de la ligne :
|
L’inertie est liée. |
Inertie de mesure 1 |
Cosinus**2 mesures 1 |
||||
|
Cadres supérieurs |
||||||
|
Cadres juniors |
||||||
|
Cadres supérieurs |
||||||
|
Employés juniors |
||||||
|
Secrétaires |
Coordonnées. La première colonne du tableau des résultats contient des coordonnées dont l'interprétation, comme déjà indiqué, dépend de la normalisation. La dimension est sélectionnée par l'utilisateur (dans cet exemple, nous avons choisi un espace unidimensionnel) et les coordonnées sont affichées pour chaque dimension (c'est-à-dire qu'une colonne de coordonnées est affichée par axe).
Poids. La masse contient les sommes de tous les éléments pour chaque ligne de la matrice de fréquence relative (c'est-à-dire pour une matrice où chaque élément contient la masse correspondante, comme mentionné ci-dessus).
Si la méthode de normalisation est sélectionnée Profils de lignes ou en option Profils de lignes et de colonnes, qui est défini par défaut, les coordonnées de ligne sont calculées à partir de la matrice de profil de ligne. En d'autres termes, les coordonnées sont calculées sur la base de la matrice de probabilité conditionnelle présentée dans la colonne Poids.
Qualité. Colonne Qualité contient des informations sur la qualité de représentation du point de ligne correspondant dans le système de coordonnées déterminé par la dimension sélectionnée. Dans le tableau en question, une seule dimension a été sélectionnée, donc les chiffres de la colonne Qualité sont la qualité de présentation des résultats dans un espace unidimensionnel. On peut constater que la qualité des cadres supérieurs est très faible, mais élevée pour les employés et secrétaires seniors et subalternes.
Notez encore une fois que, sur le plan informatique, le but de l'analyse des correspondances est de représenter les distances entre les points dans un espace de dimension inférieure.
Si la dimension maximale est utilisée (égale au nombre minimum de lignes et de colonnes moins une), toutes les distances peuvent être reproduites exactement.
La qualité d'un point est définie comme le rapport du carré de la distance d'un point donné à l'origine, dans l'espace de la dimension sélectionnée, au carré de la distance à l'origine, définie dans l'espace de la dimension maximale. (la métrique du chi carré est choisie comme métrique dans ce cas, comme mentionné précédemment). En analyse factorielle, il existe un concept similaire de généralité.
La qualité calculée par STATISTICA est indépendante de la méthode de standardisation choisie et utilise toujours la standardisation par défaut (c'est-à-dire que la métrique de distance est le chi carré et la mesure de la qualité peut être interprétée comme la fraction du chi carré définie par la ligne correspondante dans l'espace de la dimension correspondante).
Une qualité faible signifie que le nombre de dimensions disponibles ne représente pas suffisamment bien la ligne (colonne) correspondante.
Inertie relative. La qualité d'un point (voir ci-dessus) représente le rapport de la contribution d'un point donné à l'inertie totale (Chi carré), ce qui peut expliquer la dimension choisie.
La qualité ne répond pas à la question de savoir dans quelle mesure et dans quelle mesure le point correspondant contribue réellement à l'inertie (valeur du chi carré).
L'inertie relative représente la fraction de l'inertie totale appartenant à un point donné et ne dépend pas de la dimension sélectionnée par l'utilisateur. Notez que n'importe quelle solution particulière peut assez bien représenter un point (haute qualité), mais le même point peut apporter une très petite contribution à l'inertie globale (c'est-à-dire qu'une ligne de points, dont les éléments sont des fréquences relatives, est similaire à une ligne, des éléments qui sont la moyenne de toutes les lignes).
Inertie relative pour chaque dimension. Cette colonne contient la contribution relative du point de ligne correspondant à la valeur d'inertie, déterminée par la dimension correspondante. Dans le rapport, cette valeur est donnée pour chaque point (ligne ou colonne) et pour chaque mesure.
Cosinus**2 (qualité ou corrélations quadratiques avec chaque dimension). Cette colonne contient la qualité de chaque point, déterminée par la dimension correspondante. Si l'on résume les éléments des colonnes cosinus**2 ligne par ligne pour chaque dimension, le résultat est une colonne de valeurs de Qualité, déjà évoquées plus haut (puisque dans l'exemple considéré la dimension 1 a été choisie, la colonne Cosinus 2 coïncide avec la colonne Qualité). Cette valeur peut être interprétée comme la « corrélation » entre le point correspondant et la dimension correspondante. Le terme Cosinus**2 est né du fait que cette valeur est le carré du cosinus de l'angle formé par un point donné et l'axe correspondant.
Points supplémentaires. Il peut être utile d'interpréter les résultats en incluant des lignes ou des colonnes supplémentaires qui n'étaient pas initialement incluses dans l'analyse. Il est possible d'inclure à la fois des points de ligne supplémentaires et des points de colonne supplémentaires. Vous pouvez également afficher des points supplémentaires avec les points d'origine sur le même graphique. Par exemple, considérons les résultats suivants :
|
Groupe d'employés |
Cote 1 |
Cote 2 |
|
Cadres supérieurs |
||
|
Cadres juniors |
||
|
Cadres supérieurs |
||
|
Employés juniors |
||
|
Secrétaires |
||
|
moyenne nationale |
Ce tableau affiche les coordonnées (pour deux dimensions) calculées pour un tableau de fréquence constitué d'une classification du degré de tabagisme chez les employés de divers postes.
La ligne Moyenne Nationale contient les coordonnées d'un point supplémentaire, qui est le taux moyen (en pourcentage) calculé pour les différentes nationalités des fumeurs. Dans cet exemple, il s'agit uniquement de données de modèle.
Si vous construisez un diagramme bidimensionnel des groupes d'employés et de la Moyenne Nationale, vous serez immédiatement convaincu que ce point supplémentaire et le groupe des Secrétaires sont très proches l'un de l'autre et sont situés du même côté de l'axe de coordonnées horizontal avec le Catégorie non-fumeur (colonne à points). En d’autres termes, l’échantillon présenté dans le tableau de fréquence original contient plus de fumeurs que la moyenne nationale.
Bien que la même conclusion puisse être tirée en examinant le tableau de contingence original, dans des tableaux plus grands, ces conclusions ne sont bien entendu pas aussi évidentes.
Qualité de présentation des points complémentaires. Un autre résultat intéressant concernant les points supplémentaires est l’interprétation de la qualité de la représentation à une dimension donnée.
Encore une fois, le but de l’analyse des correspondances est de représenter les distances entre les coordonnées de lignes ou de colonnes dans un espace de dimension inférieure. Sachant comment ce problème est résolu, il faut répondre à la question de savoir si la représentation d'un point supplémentaire dans l'espace de la dimension choisie est adéquate (au sens des distances aux points de l'espace d'origine). Vous trouverez ci-dessous les statistiques pour les points d'origine et pour le point supplémentaire Moyenne nationale appliquées au problème dans un espace bidimensionnel.
Cadres juniors0.9998100.630578
Rappelons que la qualité des points de ligne ou de colonne est définie comme le rapport de la distance au carré du point à l'origine dans l'espace de dimension réduite à la distance au carré du point à l'origine dans l'espace d'origine (la distance du chi carré est choisi comme métrique, comme déjà noté).
Dans un certain sens, la qualité est une quantité qui explique la fraction du carré de la distance au centre de gravité du nuage de points d'origine.
Ligne de points supplémentaire La moyenne nationale a une qualité de 0,76. Cela signifie qu’un point donné est assez bien représenté dans un espace bidimensionnel. La statistique Cosinus**2 est la qualité de la représentation du point ligne correspondant, déterminée par le choix d'un espace d'une dimension donnée (si l'on additionne les éléments des colonnes Cosinus 2 ligne par ligne pour chaque dimension, alors comme un résultat nous arriverons à la valeur de Qualité obtenue précédemment).
Analyse graphique des résultats. C’est la partie la plus importante de l’analyse. Essentiellement, vous pouvez oublier les critères de qualité formels, mais suivre quelques règles simples pour comprendre les graphiques.
Ainsi, le graphique montre des points de ligne et des points de colonne. C'est une bonne pratique de présenter les deux points (après tout, nous analysons les relations entre les lignes et les colonnes du tableau !).
Typiquement l'axe horizontal correspond à l'inertie maximale. Le pourcentage d'inertie totale expliqué par une valeur propre donnée est indiqué près de la flèche. Souvent, les valeurs propres correspondantes extraites du tableau des résultats sont également indiquées. L'intersection des deux axes est le centre de gravité des points observés, correspondant aux profils moyens. Si les points sont du même type, c'est-à-dire qu'ils sont soit des lignes, soit des colonnes, plus la distance entre eux est petite, plus la relation est étroite. Afin d'établir une connexion entre des points de types différents (entre lignes et colonnes), vous devez considérer angles entre eux avec le sommet au centre de gravité.
La règle générale pour évaluer visuellement le degré de dépendance est la suivante.
- Considérons 2 points arbitraires de types différents (lignes et colonnes d'un tableau).
- Relions-les avec des segments de droite avec le centre de gravité (point de coordonnées 0,0).
- Si l’angle résultant est aigu, alors la ligne et la colonne sont positivement corrélées.
- Si l’angle résultant est obtus, alors la corrélation entre les variables est négative.
- Si l'angle est bon, il n'y a pas de corrélation.
Considérons l'analyse de données spécifiques dans le système STATISTICA.
Exemple 1 (analyse des fumeurs)
Étape 1. Exécutez le module Analyse des correspondances.
Il existe 2 types d'analyse dans la zone de lancement du module : l'analyse des correspondances et l'analyse des correspondances multivariées.
Sélectionner Analyse des correspondances. L'analyse des correspondances multivariées sera abordée dans l'exemple suivant.
Étape 2. Ouvrez le fichier de données smoking.sta dans le dossier Exemples.


Le fichier est déjà un tableau de contingence, aucune tabulation n'est donc requise. Sélectionnez le type d'analyse - Fréquences sans variable de regroupement.
Étape 3. Cliquez sur le bouton Variables avec fréquences et sélectionnez les variables à analyser.
Pour cet exemple, sélectionnez toutes les variables.

Étape 4. Cliquez sur D'ACCORD et démarrez la procédure de calcul. Une fenêtre avec les résultats apparaîtra à l'écran.

Étape 5. Regardons les résultats en utilisant les options de cette fenêtre.
Habituellement, on regarde d'abord les graphiques, pour lesquels il existe un groupe de boutons Graphique de coordonnées.
Les graphiques sont disponibles pour les lignes et les colonnes, ainsi que pour les lignes et les colonnes simultanément.
La dimension maximale de l'espace est spécifiée dans l'option Dimension.
La dimension la plus intéressante est 2. Notez que dans un graphique, surtout s'il y a beaucoup de données, les étiquettes peuvent se chevaucher, donc l'option Raccourcissez les étiquettes.
Cliquez sur le troisième bouton 2M dans la boîte de dialogue. Un graphique apparaîtra à l'écran :

Notez que le graphique montre les deux facteurs : groupe d'employés - lignes et intensité du tabagisme - colonnes.
Reliez la catégorie SENIOR EMPLOYÉS et la catégorie NON au centre de gravité à l’aide d’une ligne droite.
L'angle résultant sera aigu, ce qui dans le langage de l'analyse des correspondances indique la présence d'une corrélation positive entre ces caractéristiques (regardez le tableau original pour vous en assurer).
Les coordonnées des lignes et des colonnes peuvent également être visualisées sous forme numérique à l'aide du bouton Coordonnées des lignes et des colonnes.

En utilisant le bouton Valeurs propres, vous pouvez voir l’expansion de la statistique du chi carré en valeurs propres.
Option Calendrier Seules les mesures sélectionnées vous permettent de visualiser les coordonnées des points le long des axes sélectionnés.

Groupe d'options Afficher les tableaux dans la partie droite de la fenêtre permet de visualiser le tableau de contingence original et attendu, les différences entre fréquences et autres paramètres calculés sous l'hypothèse d'indépendance des caractéristiques tabulées (voir chapitre Construction et analyse des tableaux, test du chi carré).
Il est préférable d'explorer les grands tableaux progressivement, en introduisant des variables supplémentaires si nécessaire. Pour cela, les options suivantes sont proposées : Ajouter des points de ligne, Ajouter des points de colonne.
Exemple 2 (analyse des ventes)
Dans le chapitre Analyse et construction de tableaux, un exemple lié à l'analyse des ventes a été considéré. Appliquons l'analyse des correspondances aux données.
Il a été noté précédemment que la question de savoir quel type d'achats l'acheteur a effectué, à condition que 3 biens aient été achetés, est complexe.
En effet, nous avons 21 produits au total. Pour visualiser tous les tableaux de contingence, vous devez effectuer 21×20×19 = 7980 actions. Le nombre d'actions augmente de façon catastrophique avec l'augmentation des produits et du nombre d'attributs. Appliquons l'analyse des correspondances. Ouvrons un fichier de données avec des variables indicatrices marquant le produit acheté.

Dans le panneau de démarrage du module, sélectionnez Analyse des correspondances multivariées.

Posons la condition de sélection des observations.

Cette condition permet de sélectionner les clients ayant effectué exactement 3 achats.
Puisque nous traitons de données non tabulées, nous sélectionnerons le type d'analyse Donnée initiale(tabulation requise).
Pour faciliter une présentation graphique plus approfondie, nous sélectionnerons un petit nombre de variables. Sélectionnons également des variables supplémentaires (voir fenêtre ci-dessous).

Commençons la procédure de calcul.

Dans la fenêtre qui apparaît Résultats de l'analyse des correspondances multivariées Regardons les résultats.
À l'aide du bouton 2M, un graphique bidimensionnel de variables s'affiche.
Dans ce graphique, les variables supplémentaires sont marquées de points rouges, ce qui facilite l'analyse visuelle.
Notez que chaque variable a une valeur de 1 si l'article est acheté et une valeur de 0 si l'article n'est pas acheté.
Regardons le graphique. Choisissons, par exemple, des paires de caractéristiques proches. 
En conséquence, nous obtenons ce qui suit :

Des études similaires peuvent être réalisées pour d’autres données, lorsqu’il n’existe pas d’hypothèses a priori sur les dépendances dans les données.
STATISTIQUE propose une large gamme de méthodes d’analyse statistique exploratoire. Le système peut calculer pratiquement toutes les statistiques descriptives, y compris la médiane, le mode, les quartiles, les centiles définis par l'utilisateur, les moyennes et les écarts types, les intervalles de confiance pour la moyenne, l'asymétrie, l'aplatissement (avec leurs erreurs types), les moyennes harmoniques et géométriques et bien d'autres. statistiques descriptives. Il est possible de sélectionner des critères pour tester la normalité de la distribution (test de Kolmogorov-Smirnov, Liliefors, Shapiro-Wilks). Une large sélection de graphiques facilite l’analyse exploratoire.
2. Corrélations.
Cette section comprend un grand nombre d'outils qui vous permettent d'explorer les dépendances entre variables. Il est possible de calculer presque toutes les mesures courantes de dépendance, y compris le coefficient de corrélation de Pearson, le coefficient de corrélation de rang de Spearman, le Tau de Kendall (b, c), le Gamma, le coefficient de contingence des traits C et bien d'autres.
Des matrices de corrélation peuvent également être calculées pour les données comportant des valeurs manquantes à l'aide de méthodes spéciales de gestion des valeurs manquantes.
Des fonctionnalités graphiques spéciales vous permettent de sélectionner des points individuels sur un nuage de points et d'évaluer leur contribution à une courbe de régression ou à toute autre courbe ajustée aux données.
3. t - tests (et autres critères de différences de groupe).
Les procédures vous permettent de calculer des tests t pour des échantillons dépendants et indépendants, ainsi que des statistiques de Hotteling (voir également ANOVA/MANOVA).
4. Tableaux de fréquence et tableaux croisés.
Le module contient un ensemble complet de procédures permettant la tabulation de variables d'enquête continues, catégorielles, dichotomiques et multivariées. Les fréquences cumulées et relatives sont calculées. Des tests de fréquences croisées sont disponibles. Les statistiques de Pearson, les statistiques du maximum de vraisemblance, la correction Erc, le chi carré, les statistiques de Fisher, les statistiques de McNemer et bien d'autres sont calculées.
Module "Régression Multiple"
Le module de régression multiple comprend un ensemble complet d'outils de régression multiple linéaire et non linéaire fixe (en particulier polynomiale, exponentielle, logarithmique, etc.), y compris des méthodes pas à pas, hiérarchiques et autres, ainsi que la régression de crête.
Système STATISTIQUE vous permet de calculer un ensemble complet de statistiques et de diagnostics avancés, y compris le tableau de régression complet, les corrélations et covariances partielles et partielles pour les poids de régression, les matrices d'exécution, les statistiques de Durbin-Watson, les distances de Mahalanobis et de Cook, les résidus supprimés et bien d'autres. L'analyse des résidus et des valeurs aberrantes peut être effectuée à l'aide d'une grande variété de tracés, notamment une variété de nuages de points, de tracés de corrélation partielle et bien d'autres. Le système de prévision permet à l'utilisateur d'effectuer une analyse de simulation. Des problèmes de régression extrêmement importants sont autorisés (jusqu'à 300 variables dans une procédure de régression exploratoire). STATISTIQUE contient également un « Module d'estimation non linéaire », qui peut être utilisé pour estimer presque tous les modèles non linéaires définis par l'utilisateur, y compris la régression logit, probit, etc.
Module "Analyse de Variance". Module ANOVA/MANOVA générale
Le module ANOVA/MANOVA est un ensemble de procédures pour l'analyse générale univariée et multivariée de la variance et de la covariance.
Le module offre la plus large sélection de procédures statistiques pour tester les hypothèses de base de l'analyse de variance, en particulier les critères de Bartlett, Cochran, Hartley, Box et autres.
Module "Analyse Discriminante"
Les méthodes d'analyse discriminante permettent, sur la base d'un certain nombre d'hypothèses, de construire une règle de classification pour attribuer un objet à l'une de plusieurs classes, minimisant un critère raisonnable, par exemple la probabilité d'une fausse classification ou une fonction de perte spécifiée par l'utilisateur. Le choix du critère est déterminé par l'utilisateur en fonction du préjudice qu'il subira du fait d'erreurs de classification.
Module d'analyse discriminante du système STATISTIQUE contient un ensemble complet de procédures pour une analyse discriminante fonctionnelle par étapes multiples. STATISTIQUE vous permet d'effectuer une analyse étape par étape, à la fois en avant et en arrière, ainsi qu'au sein d'un bloc de variables défini par l'utilisateur dans le modèle.
Module « Statistiques non paramétriques et ajustement des distributions »
Le module contient un ensemble complet de tests d'ajustement non paramétriques, en particulier les tests de Kolmogorov-Smirnov, de Mann-Whitney, de Wal-da-Wolfowitz, de Wilcoxon et bien d'autres.
Tous les tests de classement implémentés sont disponibles dans le cas de classements appariés et utilisent des corrections pour les petits échantillons.
Les procédures statistiques du module permettent à l'utilisateur de comparer facilement la distribution des quantités observées avec un grand nombre de distributions théoriques différentes. Vous pouvez adapter à vos données les distributions normales, uniformes, linéaires, exponentielles, gamma, lognormales, chi carré, Weibull, Gompertz, binomiale, Poisson, géométrique et Bernoulli. La qualité de l'ajustement est évaluée à l'aide du test du chi carré ou du test de Kolmogorov-Smirnov sur un échantillon (les paramètres d'ajustement peuvent être contrôlés) ; Les tests Lillifors et Shapiro-Wilks sont également pris en charge.
Module "Analyse Factorielle"
Le module d'analyse factorielle contient un large éventail de méthodes et d'options qui fournissent à l'utilisateur des outils d'analyse factorielle complets.
Elle comprend notamment la méthode des composantes principales, la méthode du résidu minimum, la méthode du maximum de vraisemblance, etc. avec des diagnostics avancés et une gamme extrêmement large de graphiques analytiques et exploratoires. Le module peut effectuer le calcul des composantes principales de l'analyse factorielle générale et hiérarchique avec un tableau contenant jusqu'à 300 variables. L'espace des facteurs communs peut être tracé et visualisé tranche par tranche ou sous forme de nuages de points à 2 ou 3 dimensions avec des variables ponctuelles étiquetées.
Une fois la solution déterminée, l'utilisateur peut recalculer la matrice de corrélation à partir du nombre de facteurs correspondant afin d'évaluer la qualité du modèle construit.
En plus, STATISTIQUE contient le module "Multidimensionnel Scaling", le module "Reliability Analysis", le module "Cluster Analysis", le module "Log-Linear Analysis", le module "Nonlinear Estimation", le module "Canonical Correlation", l'"Lifetime Analysis" module, la série de modules « Analyse du temps » et prévisions » et d'autres.
Résultats numériques de l'analyse statistique dans le système STATISTIQUE sont affichés sous forme de feuilles de calcul spéciales, appelées tableaux de résultats - Feuilles ScroH™. les tables Feuille de défilement peut contenir n'importe quelle information (à la fois numérique et textuelle), depuis une courte ligne jusqu'à des mégaoctets de résultats. Dans le système STATISTIQUE ces informations sont sorties sous la forme d'une séquence (file d'attente), qui consiste en un ensemble de tables Feuille de défilement et des graphiques.
STATISTIQUE contient un grand nombre d'outils pour une visualisation pratique des résultats d'analyses statistiques et leur visualisation. Ils incluent des opérations standard d'édition de tables (y compris des opérations sur des blocs de valeurs, Glisser-Déposer - "Glisser-déposer", remplissage automatique des blocs, etc.), opérations de visualisation pratiques (déplacement des bordures des colonnes, défilement fractionné dans le tableau, etc.), accès aux statistiques de base et aux capacités graphiques du système STATISTIQUE. Lors de la sortie d'une plage de résultats (par exemple, une matrice de corrélation) STATISTIQUE marque des coefficients de corrélation significatifs avec la couleur. L'utilisateur a également la possibilité de mettre en évidence les valeurs nécessaires dans le tableau en utilisant la couleur Feuille de défilement.
Si l'utilisateur doit effectuer une analyse statistique détaillée des résultats intermédiaires, le tableau peut être enregistré Feuille de défilement au format fichier de données STATISTIQUE puis travaillez avec comme avec des données ordinaires.
En plus d'afficher les résultats d'analyse sous forme de fenêtres séparées avec des graphiques et des tableaux Feuille de défilement sur l'espace de travail du système STATISTIQUE, Le système a la capacité de créer un rapport dans la fenêtre duquel toutes ces informations peuvent être affichées. Un rapport est un document (au format RTF), qui peut contenir n’importe quel texte ou information graphique. DANS STATISTIQUE Il est possible de créer automatiquement un rapport, appelé rapport automatique. De plus, n'importe quelle table Feuille de défilement ou un graphique peut être automatiquement envoyé au rapport.
), etc. De plus, l’avènement des ordinateurs modernes et rapides et des logiciels libres (comme R) a rendu toutes ces méthodes à forte intensité de calcul accessibles à presque tous les chercheurs. Cependant, cette accessibilité exacerbe encore un problème bien connu de toutes les méthodes statistiques, qui en anglais est souvent décrit comme " les déchets entrent, les déchets sortent", c'est-à-dire "garbage in - garbage out". Le point ici est le suivant : les miracles ne se produisent pas, et si nous ne prêtons pas attention au fonctionnement d'une méthode particulière et aux exigences qu'elle impose aux données analysées, alors les résultats obtenus avec son aide ne peut pas être pris au sérieux. Par conséquent, chaque fois que le chercheur doit commencer son travail par une familiarisation approfondie avec les propriétés des données obtenues et en vérifiant les conditions nécessaires à l'applicabilité des méthodes statistiques correspondantes, cette étape initiale d'analyse est appelée. . exploration(L'analyse exploratoire des données).
Dans la littérature sur les statistiques, vous pouvez trouver de nombreuses recommandations pour effectuer une analyse exploratoire des données (EDA). Il y a deux ans dans le magazine Méthodes en écologie et évolution Un excellent article a été publié qui résume ces recommandations en un seul protocole de mise en œuvre de la RDA : Zuur A. F., Ieno E. N., Elphick C. S. (2010) Un protocole d'exploration des données pour éviter les problèmes statistiques courants. Méthodes en écologie et évolution 1(1): 3-14. Bien que l’article s’adresse aux biologistes (en particulier aux écologistes), les principes qui y sont énoncés s’appliquent certainement à d’autres disciplines scientifiques. Dans cet article de blog et dans les suivants, je fournirai des extraits de mon travail. Zuur et coll.(2010) et décrivent le protocole RDA proposé par les auteurs. Tout comme dans l'article original, la description des différentes étapes du protocole sera accompagnée de brèves recommandations pour l'utilisation des fonctions et packages correspondants du système R.
Le protocole proposé comprend les principaux éléments suivants :
- Formuler une hypothèse de recherche. Effectuer des expériences/observations pour collecter des données.
- L'analyse exploratoire des données:
- Identification des points de choix
- Vérifier l'homogénéité des écarts
- Vérification de la normalité de la distribution des données
- Détection d'un nombre excessif de valeurs nulles
- Identification des variables colinéaires
- Identifier la nature de la relation entre les variables analysées
- Identifier les interactions entre les variables prédictives
- Identifier les corrélations spatio-temporelles entre les valeurs des variables dépendantes
- Application d'une méthode statistique (modèle) adaptée à la situation.
Zuur et coll.(2010) notent que la RDA est plus efficace lorsqu'une variété d'outils graphiques sont utilisés, car les graphiques fournissent souvent un meilleur aperçu de la structure et des propriétés des données analysées que les tests statistiques formels.
Commençons notre examen du protocole RDA donné par identifier les points aberrants. La sensibilité des différentes méthodes statistiques à la présence de valeurs aberrantes dans les données varie. Par exemple, lors de l'utilisation d'un modèle linéaire généralisé pour analyser une variable dépendante distribuée par Poisson (par exemple, le nombre de cas d'une maladie dans différentes villes), la présence de valeurs aberrantes peut provoquer une surdispersion, rendant le modèle inapplicable. Dans le même temps, lors de l'utilisation d'une mise à l'échelle multidimensionnelle non paramétrique basée sur l'indice Jaccard, toutes les données originales sont converties en une échelle nominale à deux valeurs (1/0) et la présence de valeurs aberrantes n'affecte pas le résultat de l'analyse. Le chercheur doit clairement comprendre ces différences entre les différentes méthodes et, si nécessaire, vérifier la présence de biais dans les données. Donnons une définition pratique : par « valeur aberrante », nous entendons une observation « trop » grande ou « trop » petite par rapport à la majorité des autres observations disponibles.
Généralement utilisé pour identifier les valeurs aberrantes diagrammes de portée. Dans R, lors de la construction de diagrammes d'étendue, des estimations robustes de la tendance centrale (médiane) et de la dispersion (intervalle interquartile, IQR) sont utilisées. La moustache supérieure s'étend du haut de la boîte jusqu'à la plus grande valeur d'échantillon dans un rayon de 1,5 x IFR de cette limite. De même, la moustache inférieure s'étend de la limite inférieure de la boîte jusqu'à la plus petite valeur d'échantillon située à moins de 1,5 x IFR de cette limite. Les observations en dehors des moustaches sont considérées comme des valeurs aberrantes potentielles (Figure 1).
| Figure 1. Structure du diagramme de portée. |
Exemples de fonctions de R utilisées pour construire des diagrammes de plages :
- Fonction boxplot() de base (voir pour plus de détails).
- Package ggplot2 : objet géométrique (" géome") boîte à moustaches. Par exemple :
p<- ggplot (mtcars, aes(factor(cyl), mpg)) p + geom_boxplot() # или: qplot (factor(cyl), mpg, data = mtcars, geom = "boxplot" )
Figure 2. Diagramme de dispersion de Cleveland illustrant les données sur la longueur des ailes de 1 295 bruants (Zuur et al. 2010). Dans cet exemple, les données ont été pré-ordonnées en fonction du poids des oiseaux, le nuage de points a donc grossièrement la forme d'un S.
Sur la figure 2, le point correspondant à la longueur d'aile de 68 mm est bien visible. Cependant, cette valeur de longueur d’aile ne doit pas être considérée comme une valeur aberrante puisqu’elle n’est que légèrement différente des autres valeurs de longueur. Ce point ne se démarque du contexte général que parce que les valeurs originales de longueur d'aile ont été classées en fonction du poids des oiseaux. En conséquence, la valeur aberrante devrait plutôt être recherchée parmi les valeurs de poids (c'est-à-dire qu'une valeur de longueur d'aile très élevée (68 mm) a été notée chez un moineau qui pèse inhabituellement peu pour cette espèce).
Jusqu'à présent, nous avons qualifié de « valeur aberrante » une observation qui est « significativement » différente de la plupart des autres observations dans la population étudiée. Cependant, une approche plus rigoureuse pour identifier les valeurs aberrantes consiste à évaluer l’impact de ces observations inhabituelles sur les résultats de l’analyse. Une distinction doit être faite entre les observations inhabituelles pour les variables dépendantes et indépendantes (prédicteurs). Par exemple, lors de l'étude de la dépendance de l'abondance d'une espèce biologique à la température, la plupart des valeurs de température peuvent se situer entre 15 et 20 °C, et une seule valeur peut être égale à 25 °C. Ce dispositif expérimental est, pour le moins, imparfait, puisque la plage de température de 20 à 25°C sera inégalement étudiée. Cependant, dans les études de terrain réelles, l’opportunité d’effectuer des mesures à haute température ne se présente qu’une seule fois. Que penser alors de cette mesure inhabituelle prise à 25°C ? Avec un grand volume d'observations, ces observations rares peuvent être exclues de l'analyse. Cependant, avec une quantité de données relativement faible, une réduction encore plus importante peut s'avérer indésirable du point de vue de la signification statistique des résultats obtenus. Si la suppression des valeurs inhabituelles d'un prédicteur n'est pas possible pour une raison ou une autre, une transformation de ce prédicteur (par exemple, un logarithme) peut aider.
Il est plus difficile de « lutter » contre des valeurs inhabituelles de la variable dépendante, notamment lors de la construction de modèles de régression. La transformation par exemple par logarithme peut aider, mais comme la variable dépendante présente un intérêt particulier dans la construction de modèles de régression, il est préférable d'essayer de trouver une méthode d'analyse basée sur une distribution de probabilité permettant une plus grande répartition des valeurs pour de grandes moyennes (par exemple, une distribution gamma pour les variables continues ou une distribution de Poisson pour les variables quantitatives discrètes). Cette approche vous permettra de travailler avec les valeurs originales de la variable dépendante.
En fin de compte, la décision de supprimer les valeurs inhabituelles de l'analyse appartient au chercheur. Dans le même temps, il doit se rappeler que les raisons de telles observations peuvent être différentes. Ainsi, la suppression des valeurs aberrantes résultant d’une mauvaise conception expérimentale (voir l’exemple de température ci-dessus) peut être tout à fait justifiée. Il serait également justifié de supprimer les valeurs aberrantes qui résultent clairement d’erreurs de mesure. Cependant, des observations inhabituelles parmi les valeurs de la variable dépendante peuvent nécessiter une approche plus nuancée, surtout si elles reflètent la variabilité naturelle de cette variable. À cet égard, il est important de conserver une documentation détaillée des conditions dans lesquelles se déroule la partie expérimentale de l’étude – cela peut aider à interpréter les « valeurs aberrantes » lors de l’analyse des données. Quelles que soient les raisons de l'apparition d'observations inhabituelles, il est important dans le rapport scientifique final (par exemple, dans un article) d'informer le lecteur à la fois sur le fait que de telles observations ont été identifiées et sur les mesures prises à leur égard.
1. Le concept d'exploration de données. Méthodes d'exploration de données.
Répondre:L'exploration de données consiste à identifier des modèles ou des relations cachés entre des variables dans de grandes quantités de données brutes. Généralement divisé en problèmes de classification, de modélisation et de prévision. Processus de recherche automatique de modèles dans de grands ensembles de données. Le terme Data Mining a été inventé par Grigory Pyatetsky-Shapiro en 1989.
2. Le concept d'analyse exploratoire des données. Quelle est la différence entre la procédure de Data Mining et les méthodes d’analyse de données statistiques classiques ?
Répondre:L'analyse exploratoire des données (EDA) est utilisée pour trouver des relations systématiques entre des variables dans des situations où il n'y a pas (ou pas suffisamment) d'idées a priori sur la nature de ces relations.
Les méthodes traditionnelles d’analyse des données se concentrent principalement sur le test d’hypothèses préformulées et sur l’analyse exploratoire « grossière », tandis que l’un des principes fondamentaux du Data Mining est la recherche de modèles non évidents.
3. Méthodes d’analyse graphique exploratoire des données. Outils Statistica pour l’analyse graphique exploratoire des données.
Répondre:À l’aide de méthodes graphiques, vous pouvez trouver des dépendances, des tendances et des biais « cachés » dans des ensembles de données non structurés.
Outils Statistica pour l'analyse exploratoire graphique : graphiques radiaux catégorisés, histogrammes (2D et 3D).
Répondre:Ces tracés sont des collections de tracés bidimensionnels, tridimensionnels, ternaires ou à n dimensions (tels que des histogrammes, des nuages de points, des tracés linéaires, des surfaces, des diagrammes circulaires), un tracé pour chaque catégorie (sous-ensemble) d'observations sélectionnée.
5. Quelles informations sur la nature des données peuvent être obtenues en analysant des nuages de points et des nuages de points catégorisés ?
Répondre:Les nuages de points sont couramment utilisés pour révéler la nature de la relation entre deux variables (par exemple, le bénéfice et la masse salariale), car ils fournissent beaucoup plus d'informations que le coefficient de corrélation.
6. Quelles informations sur la nature des données peuvent être obtenues à partir de l'analyse des histogrammes et des histogrammes catégorisés ?
Répondre:Les histogrammes sont utilisés pour examiner les distributions de fréquence des valeurs variables. Cette distribution de fréquence montre quelles valeurs spécifiques ou plages de valeurs de la variable d'intérêt se produisent le plus souvent, à quel point ces valeurs sont différentes, si la plupart des observations se situent autour de la moyenne, si la distribution est symétrique ou asymétrique, multimodale (c'est-à-dire qu'il a deux pics ou plus), ou unimodal, etc. Les histogrammes sont également utilisés pour comparer les distributions observées et théoriques ou attendues.
Les histogrammes catégorisés sont des ensembles d'histogrammes correspondant à différentes valeurs d'une ou plusieurs variables catégorisantes ou des ensembles de conditions logiques de catégorisation.
7. En quoi les graphiques catégorisés sont-ils fondamentalement différents des graphiques matriciels du système Statistica ?
Répondre:Les tracés matriciels se composent également de plusieurs tracés ; cependant, ici, chacun est (ou peut être) basé sur le même ensemble d'observations, et les graphiques sont tracés pour toutes les combinaisons de variables d'une ou deux listes. Les tracés catégorisés nécessitent le même choix de variables que les tracés non catégorisés du type correspondant (par exemple, deux variables pour un nuage de points). Parallèlement, pour les graphiques catégorisés, il est nécessaire de spécifier au moins une variable de regroupement (ou un moyen de diviser les observations en catégories), qui contiendrait des informations sur l'appartenance de chaque observation à un sous-groupe spécifique. La variable de regroupement ne sera pas directement tracée (c'est-à-dire qu'elle ne sera pas tracée), mais elle servira de critère pour diviser toutes les observations analysées en sous-groupes distincts. Pour chaque groupe (catégorie) défini par la variable de regroupement, un graphique sera tracé.
8. Quels sont les avantages et les inconvénients des méthodes graphiques pour l'analyse exploratoire des données ?
Répondre:+ Clarté et simplicité.
- Les méthodes donnent des valeurs approximatives.
9. Quelles méthodes d'analyse des données exploratoires primaires connaissez-vous ?
Répondre:Méthodes statistiques, réseaux de neurones.
10. Comment tester l'hypothèse sur l'accord de la distribution des données d'échantillon avec le modèle de distribution normale dans le système Statistica ?
Répondre:La distribution x2 (chi carré) avec n degrés de liberté est la distribution de la somme des carrés de n variables aléatoires normales standard indépendantes.
Le chi carré est une mesure de différence. Nous fixons le niveau d'erreur à a=0,05. En conséquence, si la valeur p>a, alors la distribution est optimale.
- pour tester l'hypothèse sur l'accord de la distribution des données d'échantillon avec le modèle de distribution normale à l'aide du test du chi carré, sélectionnez l'élément de menu Statistiques/Ajustements de distribution. Ensuite, dans la boîte de dialogue Ajustement de la distribution litigieuse, définissez le type de distribution théorique sur Normal, sélectionnez la variable sur Variables et définissez les paramètres d'analyse sur Paramètres.
11. Quelles caractéristiques statistiques de base des variables quantitatives connaissez-vous ? Leur description et leur interprétation en fonction du problème à résoudre.
Répondre:Caractéristiques statistiques de base des variables quantitatives :
espérance mathématique (volume de production moyen parmi les entreprises)
médian
écart type (racine carrée de la variance)
dispersion (une mesure de la propagation d'une variable aléatoire donnée, c'est-à-dire son écart par rapport à l'espérance mathématique)
coefficient d'asymétrie (Nous déterminons le déplacement par rapport au centre de symétrie selon la règle : si B1>0, alors le déplacement est vers la gauche, sinon - vers la droite.)
coefficient d'aplatissement (proche de la distribution normale)
valeur d'échantillon minimale, valeur d'échantillon maximale,
propagé
Coefficient de corrélation partielle (mesure le degré de proximité entre les variables, à condition que les valeurs des variables restantes soient fixées à un niveau constant).
Qualité:
Coefficient de corrélation de rang de Spearman (utilisé dans le but d'étudier statistiquement la relation entre les phénomènes. Les objets étudiés sont ordonnés par rapport à une certaine caractéristique, c'est-à-dire qu'on leur attribue des numéros de série - des rangs.)
Littérature
1. Ayvazyan S.A., Enyukov I.S., Meshalkin L.D. Statistiques appliquées : Fondamentaux de la modélisation et du traitement des données primaires. - M. : « Finances et Statistiques », 1983. - 471 p.
2. Borovikov V.P. Statistique. L'art de l'analyse des données sur ordinateur : pour les professionnels. 2e éd. - Saint-Pétersbourg : Peter, 2003. - 688 p.
3. Borovikov V.P., Borovikov I.P. Statistica - Analyse statistique et traitement de données dans l'environnement Windows. - M. : "Filin", 1997. - 608 p.
4. Manuel électronique StatSoft sur l'analyse des données.




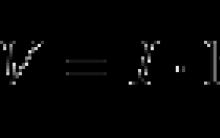





Description de poste de contremaître d'une organisation de construction
Contrôle contre signature : comment s'inscrire ?
Étapes de construction et conditions d'élaboration de la politique du personnel Conditions d'élaboration de la politique du personnel
Chuk et Gek lisent l'intégralité avec des illustrations
Journée des Héros de la Patrie, présentation pour un cours (7e année) sur le thème Présentation des Héros de la Patrie pour l'école primaire