Chaque fois que nous échouons à une autre version, c'est une histoire. Les coupables apparaissent immédiatement, et souvent c'est nous, les testeurs. C'est peut-être le destin - être le dernier maillon de cycle de la vie Logiciel, donc même si un développeur passe beaucoup de temps à écrire du code, personne ne pense même que les tests sont aussi des personnes avec certaines capacités.
Vous ne pouvez pas sauter au-dessus de votre tête, mais vous pouvez travailler 10 à 12 heures par jour. J'ai entendu de telles phrases très souvent)))
Lorsque les tests ne répondent pas aux besoins de l'entreprise, la question se pose alors de savoir pourquoi tester du tout s'ils n'ont pas le temps de travailler à temps. Personne ne pense à ce qui s'est passé avant, pourquoi les exigences n'ont pas été écrites correctement, pourquoi l'architecture n'a pas été pensée, pourquoi le code était tordu. Mais lorsque vous avez un délai et que vous n'avez pas le temps de terminer les tests, ils commencent immédiatement à vous punir ...
Mais c'était quelques mots sur la vie difficile d'un testeur. Maintenant au point 🙂
Après quelques erreurs de ce genre, tout le monde commence à se demander ce qui ne va pas dans notre processus de test. Peut-être que vous, en tant que leader, comprenez les problèmes, mais comment les transmettez-vous à la direction ? Question?
La gestion a besoin de chiffres, de statistiques. Mots simples- ils vous ont écouté, ont hoché la tête, ont dit - "Allez, fais-le" et c'est tout. Après cela, tout le monde attend un miracle de votre part, mais même si vous avez fait quelque chose et que cela n'a pas fonctionné pour vous, vous ou votre chef obtenez à nouveau un chapeau.
Tout changement doit être soutenu par la direction, et pour que la direction le soutienne, elle a besoin de chiffres, de mesures, de statistiques.
Plusieurs fois, j'ai vu comment ils essayaient de télécharger diverses statistiques à partir de trackers de tâches, en disant que "Nous supprimons les métriques de JIRA". Mais comprenons ce qu'est une métrique.
Une métrique est une valeur techniquement ou procéduralement mesurable qui caractérise l'état de l'objet de contrôle.
Voyons voir - notre équipe trouve 50 défauts lors des tests d'acceptation. C'est beaucoup? Ou peu ? Ces 50 défauts vous renseignent-ils sur l'état de l'objet de contrôle, en particulier sur le processus de test ?
Probablement pas.
Et si on vous disait que le nombre de défauts constatés lors des tests d'acceptation est de 80%, alors qu'il ne devrait être que de 60%. Je pense qu'il est immédiatement clair qu'il y a beaucoup de défauts, respectivement, pour ne pas dire plus, le code des développeurs est complètement g ... .. insatisfaisant en termes de qualité.
Quelqu'un peut dire que pourquoi alors tester? Mais je dirai que les défauts testent le temps, et le temps de test est ce qui affecte directement notre délai.
Par conséquent, nous n'avons pas seulement besoin de métriques, nous avons besoin de KPI.
KPI est une métrique qui sert d'indicateur de l'état de l'objet de contrôle. Une condition préalable est la présence d'une valeur cible et de tolérances établies.
Autrement dit, toujours, lors de la construction d'un système de métriques, vous devez avoir un objectif et des écarts autorisés.
Par exemple, vous avez besoin (votre objectif) que 90 % de tous les défauts soient résolus dès la première itération. En même temps, vous comprenez que ce n'est pas toujours possible, mais même si le nombre de défauts résolus la première fois est de 70%, c'est aussi bien.
Autrement dit, vous vous fixez un objectif et un écart acceptable. Maintenant, si vous comptez les défauts de la version et obtenez une valeur de 86%, alors ce n'est certainement pas bon, mais ce n'est plus un échec.
Mathématiquement, cela ressemblera à:
Pourquoi 2 formules ? Cela est dû au fait qu'il existe un concept de métriques ascendantes et descendantes, c'est-à-dire lorsque notre valeur cible approche 100 % ou 0 %.
Ceux. si nous parlons, par exemple, du nombre de défauts trouvés après la mise en œuvre en exploitation commerciale, alors moins il y en a, mieux c'est, et si nous parlons de couvrir la fonctionnalité avec des cas de test, alors tout ira dans l'autre sens.
Dans le même temps, n'oubliez pas comment calculer telle ou telle métrique.
Afin d'obtenir les pourcentages, les pièces, etc. dont nous avons besoin, nous devons calculer chaque métrique.
A titre d'exemple illustratif, je vais vous parler de la métrique « Rapidité de traitement des défauts par les tests ».
En utilisant une approche similaire, que j'ai décrite ci-dessus, nous formons également un KPI pour la métrique basée sur les valeurs cibles et les écarts.
Ne vous inquiétez pas, ce n'est pas aussi difficile dans la vraie vie que sur la photo !

Ce que nous avons?
Eh bien, il est clair que le numéro de version, le numéro d'incident ....
Critique - cotes. 5,
Majeur - cotes. 3,
Mineur - cotes. 1.5.
Ensuite, vous devez spécifier le SLA pour le temps de traitement des défauts. Pour ce faire, la valeur cible et le temps de retest maximal autorisé sont déterminés, de la même manière que je l'ai décrit ci-dessus pour le calcul des métriques.
Pour répondre à ces questions, nous allons passer directement à la mesure de performance et poser la question tout de suite. Et comment calculer l'indicateur si la valeur d'une demande peut être égale à "zéro". Si un ou plusieurs indicateurs sont égaux à zéro, alors l'indicateur final diminuera beaucoup, la question se pose donc de savoir comment équilibrer notre calcul pour que les valeurs nulles, par exemple, des demandes avec un facteur de gravité de « 1 », n'affectent pas beaucoup affecter notre évaluation finale.
Le poids est la valeur dont nous avons besoin pour avoir le moins d'impact des requêtes sur le score final avec une faible sévérité, et inversement, une requête avec la plus forte sévérité a un impact sérieux sur le score, à condition que nous soyons en retard sur cette requête.
Afin que vous n'ayez pas d'incompréhension dans les calculs, nous allons introduire des variables spécifiques pour le calcul :
x est le temps réel passé à retester le défaut ;
y est l'écart maximal admissible ;
z est le facteur de gravité.

Ou en langage courant, c'est :
O=ESLI(X<=y,1,(x/y)^z)
Ainsi, même si nous sommes allés au-delà des limites de SLA que nous nous sommes fixées, notre demande, en fonction de la gravité, n'affectera pas sérieusement notre score final.
Tout comme décrit ci-dessus:
X– temps réel passé à retester le défaut;
y– l'écart maximal admissible;
z est le facteur de gravité.
h- temps prévu selon SLA
Je ne sais plus comment exprimer cela dans une formule mathématique, je vais donc écrire dans un langage de programmation avec l'opérateur SI.
R = SI(x<=h;1;ЕСЛИ(x<=y;(1/z)/(x/y);0))
En conséquence, nous obtenons que si nous avons atteint l'objectif, alors notre valeur de demande est égale à 1, si nous sommes allés au-delà de l'écart autorisé, alors la note est égale à zéro et les poids sont calculés.
Si notre valeur se situe entre la cible et l'écart maximal autorisé, alors en fonction du facteur de gravité, notre valeur varie dans la plage .
Je vais maintenant donner quelques exemples de ce à quoi cela ressemblera dans notre système de métriques.
Chaque demande a son propre SLA en fonction de son importance (facteur de gravité).
Que voyons-nous ici.
Dans la première demande, nous n'avons dévié de notre valeur cible que d'une heure et avons déjà une note de 30 %, tandis que dans la deuxième demande, nous n'avons également dévié que d'une heure, mais la somme des indicateurs n'est déjà pas de 30 %, mais 42,86 %. Autrement dit, les coefficients de sévérité jouent un rôle important dans la formation de l'indicateur final de la requête.
Dans le même temps, dans la troisième demande, nous avons violé le temps maximum autorisé et la note est égale à zéro, mais le poids de la demande a changé, ce qui nous permet de calculer plus correctement l'impact de cette demande sur le coefficient final.
Eh bien, pour vous en assurer, vous pouvez simplement calculer que la moyenne arithmétique des indicateurs sera de 43,21%, et nous avons obtenu 33,49%, ce qui indique un impact sérieux des demandes de grande importance.
Modifions les valeurs dans le système à 1 heure.

dans le même temps, pour la 5ème priorité, la valeur a changé de 6% et pour la troisième - de 5,36%.
Encore une fois, l'importance d'une requête affecte son score.
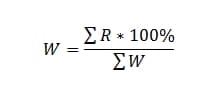
Ça y est, nous obtenons l'indicateur final de la métrique.
Qu'est-ce qui est important !
Je ne dis pas que l'utilisation du système de métriques doit se faire par analogie avec mes valeurs, je propose juste une approche pour les maintenir et les collecter.
Dans une organisation, j'ai vu qu'ils développaient leur propre cadre pour collecter des métriques à partir de HP ALM et JIRA. C'est vraiment cool. Mais il est important de se rappeler qu'un tel processus de maintien des métriques nécessite un respect sérieux des processus réglementaires.
Eh bien, et surtout, vous seul pouvez décider comment et quelles mesures vous collectez. Vous n'avez pas besoin de copier les métriques que vous ne pouvez pas collecter.
L'approche est complexe mais efficace.
Essayez-le et peut-être que vous le pouvez aussi!
Alexander Meshkov, directeur des opérations chez Performance Lab, a plus de 5 ans d'expérience dans les tests de logiciels, la gestion des tests et le conseil en assurance qualité. Expert ISTQB, TPI, TMMI.
Le test logiciel est l'évaluation du logiciel/produit en cours de développement pour vérifier ses capacités, ses capacités et sa conformité avec les résultats attendus. Il existe différents types de méthodes utilisées dans le domaine des tests et de l'assurance qualité et seront discutées dans cet article.
Les tests logiciels font partie intégrante du cycle de développement logiciel.
Qu'est-ce que le test logiciel ?
Le test logiciel n'est rien de plus que de tester un morceau de code dans des conditions de fonctionnement contrôlées et non contrôlées, d'observer la sortie, puis d'examiner s'il répond à des conditions prédéfinies.
Divers ensembles de cas de test et de stratégies de test visent à atteindre un objectif commun : éliminer les bogues et les erreurs dans le code et garantir des performances logicielles précises et optimales.
Méthodologie des tests
Les méthodes de test couramment utilisées sont les tests unitaires, les tests d'intégration, les tests d'acceptation et les tests système. Le logiciel est soumis à ces tests dans un ordre précis.
3) Test du système
4) Essais d'acceptation
La première étape est un test unitaire. Comme son nom l'indique, il s'agit d'une méthode de test au niveau de l'objet. Les composants logiciels individuels sont testés pour les erreurs. Ce test nécessite une connaissance précise du programme et de chaque module installé. Ainsi, cette vérification est effectuée par des programmeurs et non par des testeurs. Pour ce faire, des codes de test sont créés pour vérifier si le logiciel se comporte comme prévu.

Les modules individuels qui ont déjà été testés à l'unité sont intégrés les uns aux autres et vérifiés pour les défauts. Ce type de test identifie principalement les erreurs d'interface. Les tests d'intégration peuvent être effectués à l'aide d'une approche descendante, en suivant la conception architecturale du système. Une autre approche est l'approche ascendante, qui se fait à partir du bas du flux de contrôle.
Test du système
Dans ce test, l'ensemble du système est vérifié pour les erreurs et les bogues. Ce test est réalisé en interfaçant les composants matériels et logiciels de l'ensemble du système, puis il est testé. Ce test est répertorié sous la méthode de test "boîte noire", où les conditions de fonctionnement attendues du logiciel par l'utilisateur sont vérifiées.
Essais d'acceptation
Il s'agit du dernier test effectué avant la remise du logiciel au client. Elle est effectuée pour s'assurer que le logiciel qui a été développé répond à toutes les exigences du client. Il existe deux types de tests d'acceptation - l'un effectué par les membres de l'équipe de développement est appelé test d'acceptation interne (test Alpha) et l'autre effectué par le client est appelé test d'acceptation externe.
Lorsque les tests sont effectués avec l'aide de clients potentiels, on parle de tests d'acceptation par les clients. Lorsque les tests sont effectués par l'utilisateur final du logiciel, on parle de tests d'acceptation (tests bêta).
Il existe plusieurs méthodes de test de base qui font partie du régime de test des logiciels. Ces tests sont généralement considérés comme autosuffisants pour trouver des erreurs et des bogues dans tout le système.
Test de la boîte noire
Les tests de boîte noire sont effectués sans aucune connaissance du fonctionnement interne du système. Le testeur incitera le logiciel de l'environnement utilisateur en fournissant diverses entrées et en testant les sorties générées. Ce test est également connu sous le nom de test en boîte noire, en boîte fermée ou en test fonctionnel.
Essais en boîte blanche
Le test boîte blanche, contrairement au test boîte noire, prend en compte le fonctionnement interne et la logique du code. Pour effectuer ce test, le testeur doit avoir une connaissance du code pour connaître la partie exacte du code qui comporte des erreurs. Ce test est également connu sous le nom de test White-box, Open-Box ou Glass box.
Test de la boîte grise
Le test de la boîte grise, ou test de la boîte grise, est un croisement entre les tests de la boîte blanche et de la boîte noire, où le testeur n'a que les connaissances générales du produit nécessaires pour effectuer le test. Cette vérification est effectuée par le biais de la documentation et du diagramme de flux d'informations. Les tests sont effectués par l'utilisateur final ou par des utilisateurs qui semblent être des utilisateurs finaux.
Tests non fonctionnels

La sécurité des applications est l'une des tâches principales du développeur. Les tests de sécurité vérifient la confidentialité, l'intégrité, l'authentification, la disponibilité et la non-répudiation des logiciels. Des tests individuels sont effectués afin d'empêcher tout accès non autorisé au code du programme.

Le test de résistance est une technique dans laquelle le logiciel est exposé à des conditions qui sont en dehors des conditions de fonctionnement normales du logiciel. Après avoir atteint le point critique, les résultats sont enregistrés. Ce test détermine la stabilité de l'ensemble du système.

Le logiciel est testé pour sa compatibilité avec des interfaces externes telles que des systèmes d'exploitation, des plates-formes matérielles, des navigateurs Web, etc. Le test de compatibilité vérifie si le produit est compatible avec n'importe quelle plate-forme logicielle.

Comme son nom l'indique, cette technique de test teste la quantité de code ou de ressources utilisées par un programme pour effectuer une seule opération.

Ce test teste l'aspect de la convivialité et de l'utilisabilité du logiciel. La facilité avec laquelle un utilisateur peut accéder à un appareil constitue le principal point de test. Les tests d'utilisabilité couvrent cinq aspects des tests : capacité d'apprentissage, performances, satisfaction, mémorisation et erreurs.
Tests dans le processus de développement logiciel

Le modèle en cascade utilise une approche descendante, qu'il soit utilisé pour le développement ou les tests de logiciels.
Les principales étapes impliquées dans cette méthodologie de test de logiciel sont :
- Analyse des besoins
- Essai de conception
- Test de mise en œuvre
- Tester, déboguer et vérifier le code ou le produit
- Mise en œuvre et maintenance
Dans cette technique, vous ne passez à l'étape suivante qu'après avoir terminé la précédente. Le modèle utilise une approche non itérative. Le principal avantage de cette méthodologie est son approche simplifiée, systématique et orthodoxe. Cependant, il présente de nombreux inconvénients, car les bogues et les bogues dans le code ne seront découverts qu'au cours de la phase de test. Cela peut souvent entraîner une perte de temps, d'argent et d'autres ressources précieuses.
Modèle agile
Cette méthodologie repose sur une combinaison sélective d'une approche séquentielle et itérative, en plus d'une assez grande variété de nouvelles méthodes de développement. Le développement rapide et progressif est l'un des principes clés de cette méthodologie. L'accent est mis sur l'obtention de résultats rapides, pratiques et visibles. L'interaction et la participation continues des clients font partie intégrante de l'ensemble du processus de développement.
Développement rapide d'applications (RAD). Méthodologie de développement rapide d'applications
Le nom parle de lui-même. Dans ce cas, la méthodologie adopte une approche évolutive rapide, utilisant le principe de la construction de composants. Après avoir compris les différentes exigences d'un projet donné, un prototype rapide est préparé puis comparé à l'ensemble attendu de conditions et de normes de sortie. Les changements et modifications nécessaires sont apportés après une discussion commune avec le client ou l'équipe de développement (dans le cadre des tests logiciels).
Bien que cette approche ait sa part d'avantages, elle peut ne pas être appropriée si le projet est de grande envergure, complexe ou de nature extrêmement dynamique, dans lequel les exigences changent constamment.
modèle en spirale
Comme son nom l'indique, le modèle en spirale est basé sur une approche où il y a un certain nombre de cycles (ou spirales) à partir de toutes les étapes successives du modèle en cascade. Une fois le cycle initial terminé, une analyse et un examen approfondis du produit ou du résultat obtenu sont effectués. Si la sortie ne répond pas aux exigences spécifiées ou aux normes attendues, un deuxième cycle est effectué, et ainsi de suite.
Processus unifié rationnel (RUP). Processus unifié rationnel
La méthodologie RUP est également similaire au modèle en spirale, en ce sens que l'ensemble de la procédure de test est divisé en plusieurs cycles. Chaque cycle se compose de quatre étapes - création, développement, construction et transition. À la fin de chaque cycle, le produit/rendement est examiné et un autre cycle (composé des quatre mêmes phases) suit au besoin.
L'utilisation des technologies de l'information augmente chaque jour et l'importance de tests logiciels appropriés a considérablement augmenté. De nombreuses entreprises maintiennent à cet effet un personnel d'équipes spéciales, dont les capacités se situent au niveau des développeurs.
Au besoin : pour évaluer le relationnel au sein de l'équipe, l'intérêt des employés à obtenir des résultats et leur motivation.
Essai de bécasse
Instruction
Lisez les énoncés qui décrivent votre équipe et encerclez les chiffres de ceux avec lesquels vous êtes d'accord. Si vous pensez que l'énoncé n'est pas entièrement vrai, laissez le champ de réponse vide.
Ne passez pas trop de temps à réfléchir à chaque énoncé : quelques secondes suffisent.
Rappelez-vous que les résultats n'auront de sens que si vous êtes sincère.
Test
1. Notre équipe excelle dans le leadership.
2. Les décisions semblent nous être imposées.
3. Les gens ne sont pas encouragés à s'exprimer.
4. Dans une situation difficile, chacun reprend ses intérêts.
5. La communication doit être améliorée.
6. Les décisions sont prises à un niveau hiérarchique inadéquat.
7. Certains managers ne sont pas sincères avec eux-mêmes.
8. Nous remettons rarement en question la substance ou l'utilité de nos réunions.
9. Opportunités de développement insuffisantes créées.
10. Nous nous disputons souvent avec d'autres divisions.
11. Les membres de l'équipe ne communiquent pas bien entre eux.
12. Il est clair ce que l'organisation attend de notre équipe.
13. La commande acceptée est rarement remise en cause.
14. En réalité, personne ne sait où nous allons.
15. Les gens ne disent pas ce qu'ils pensent vraiment.
16. Les gens ont la position "ma hutte est sur le bord".
17. Dans une équipe, le conflit est destructeur.
18. Les décisions sont fondées sur des informations inadéquates.
19. Certains managers ne sont pas dignes de confiance.
20. Nous n'apprenons pas de nos erreurs.
21. Les managers n'aident pas leurs subordonnés à apprendre.
22. Les relations avec les autres groupes sont cool.
23. Nous ne pensons pas bien à notre position au sein de l'organisation.
24. Notre équipe est "politiquement" réceptive.
25. Nous nous retrouvons souvent sans les bonnes qualifications.
26. Nous sommes tous très occupés, mais il semble que nous n'ayons pas le temps pour tout.
27. Les questions controversées se cachent sous le tapis.
28. Cela aiderait si les gens étaient plus disposés à admettre leurs erreurs.
29. Il y a de la méfiance et de l'hostilité.
30. Les gens ne sont pas autorisés à prendre des décisions.
31. Peu de loyauté envers l'équipe.
32. Les opinions de l'extérieur ne sont pas les bienvenues.
33. Devrait avoir une grande rotation du travail.
34. Nous travaillons rarement efficacement avec d'autres équipes.
35. Nous n'avons pas assuré la coopération avec d'autres équipes et unités.
36. La capacité à travailler en équipe est un critère de sélection pour l'admission dans cette organisation.
37. Personne n'établit les liens nécessaires avec d'autres groupes.
38. Nous ne passons pas le temps nécessaire à planifier l'avenir.
39. Les questions délicates sont évitées.
40. Il arrive que quelqu'un ait été « poignardé dans le dos ».
41. Nous ne travaillons pas vraiment ensemble.
42. Les mauvaises personnes prennent des décisions.
43. Les managers sont faibles et ne sont pas prêts à se battre et à exiger l'attention sur leur point de vue.
44. Je ne reçois pas assez de commentaires.
45. Des types de compétences inappropriés sont développés.
46. L'aide ne viendra pas d'autres parties de l'organisation.
47. Il y a une forte incompréhension entre notre équipe et les syndicats qui font pression sur nous.
48. Le travail d'équipe est récompensé dans cette organisation.
49. Nous n'accordons pas assez d'attention aux relations.
50. Nous n'avons pas une idée claire de ce qu'on attend de nous.
51. L'honnêteté n'est pas un trait caractéristique de notre équipe.
52. Je ne ressens pas le soutien de mes collègues.
53. Les compétences et les informations ne sont pas bien réparties.
54. Il y a des personnalités fortes qui suivent leur propre chemin.
55. Le respect de soi est mal vu.
56. Nous devrions passer plus de temps à discuter des méthodes de travail.
57. Les managers ne prennent pas le développement personnel au sérieux.
58. D'autres parties de l'organisation ne nous comprennent pas.
59. Nous ne parvenons pas à faire passer notre message au monde extérieur.
60. Les membres de l'équipe ont de bonnes relations avec les autres membres de l'organisation.
61. Souvent, nous prenons des décisions trop rapidement.
62. Une ligne de conduite qui valorise l'individu n'a pas grand-chose à voir avec ce qui a été réalisé.
63. Trop de secrets.
64. Le conflit est évité.
65. Les désaccords corrompent.
66. L'engagement envers les solutions est faible.
67. Nos gestionnaires croient qu'une plus grande surveillance améliore les résultats.
68. Trop d'interdictions dans notre équipe.
69. Il est clair qu'il existe de meilleures opportunités dans une autre unité.
70. Nous dépensons beaucoup d'énergie pour protéger nos frontières.
71. Les membres de l'équipe ne comprennent pas ce qu'on attend d'eux.
72. La culture de l'organisation encourage le travail d'équipe.
73. Nous n'accordons pas assez d'attention aux nouvelles idées.
74. Les priorités ne sont pas claires.
75. La population n'est pas suffisamment impliquée dans la prise de décision.
76. Trop d'accusations et de reproches mutuels.
77. Ils n'écoutent pas toujours.
78. Nous n'utilisons pas pleinement les compétences dont nous disposons.
79. Les managers pensent que les gens sont intrinsèquement paresseux.
80. Nous passons beaucoup de temps à faire et pas assez de temps à réfléchir.
81. Le désir de l'individu de grandir n'est pas encouragé.
82. Nous n'essayons pas de comprendre le point de vue des autres équipes.
83. Nous n'écoutons pas nos clients.
84. L'équipe travaille conformément aux objectifs de l'organisation.
Merci pour les réponses !
La clé du test de la bécasse pour évaluer la performance d'une équipe
La description
Le test Woodcock est conçu pour mesurer la performance de l'équipe. Permet d'évaluer le relationnel dans l'équipe, l'intérêt des employés à obtenir des résultats et leur motivation. La loyauté de l'entreprise et le niveau d'interaction entre les départements de l'organisation sont également pris en compte.
Le principe du test est simple. Chaque membre de l'équipe, quel que soit son poste, remplit un questionnaire comprenant 84 énoncés. Ensuite, selon un tableau spécial, les résultats sont calculés et analysés.
Si vous doutez que les membres de l'équipe répondent honnêtement aux questions, essayez d'assurer l'anonymat des tests. Dans l'ensemble, c'est déjà un indicateur de la relation au sein de l'équipe. Néanmoins, les tests sont toujours utiles, car leurs résultats permettent d'identifier plus précisément les lacunes dans le travail de l'équipe.
De plus, il est très utile de comparer les résultats des tests des managers et de leurs subordonnés. Cela vous permet d'évaluer l'ambiance au sein de l'équipe et de déterminer le degré de confiance des subordonnés envers la direction.
Clé de l'épreuve
Transférez les réponses surlignées du questionnaire au tableau des résultats. Comptez le nombre de points dans chaque colonne. Écrivez la quantité dans la ligne "Total".
Tableau des résultats
| MAIS | À | DE | ré | E | F | g | H | je | J | À | L | |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | |
| 37 | 38 | 39 | 40 | 41 | 42 | 43 | 44 | 45 | 46 | 47 | 48 | |
| 49 | 50 | 51 | 52 | 53 | 54 | 55 | 56 | 57 | 58 | 59 | 60 | |
| 61 | 62 | 63 | 64 | 65 | 66 | 67 | 68 | 69 | 70 | 71 | 72 | |
| 73 | 74 | 75 | 76 | 77 | 78 | 79 | 70 | 81 | 82 | 83 | 84 | |
| Total |
Transférez le nombre de colonnes de la ligne "Total" vers le tableau.
Ces dernières années, les tests automatisés sont devenus une tendance dans le domaine du développement de logiciels, en un sens, sa mise en œuvre est devenue un « flux à la mode ». Cependant, la mise en œuvre et le support des tests automatisés est une procédure très gourmande en ressources et, par conséquent, coûteuse. L'utilisation généralisée de cet outil entraîne le plus souvent des pertes financières importantes sans résultat significatif.
Comment pouvez-vous utiliser un outil assez simple pour évaluer l'efficacité possible de l'utilisation d'autotests sur un projet ?
Qu'entend-on par "efficacité" de l'automatisation des tests ?
La façon la plus courante d'évaluer l'efficacité (principalement économique) est calcul du retour sur investissement(ROI). Il est calculé très simplement, étant le rapport des bénéfices aux coûts. Dès que la valeur du retour sur investissement dépasse un, la solution restitue les fonds investis et commence à en apporter de nouveaux.
Dans le cas de l'automatisation, le profit signifie économies sur les tests manuels. De plus, le profit dans ce cas peut ne pas être évident - par exemple, les résultats de la recherche de défauts dans le processus de test ad hoc par des ingénieurs, dont le temps a été libéré en raison de l'automatisation. Un tel bénéfice est assez difficile à calculer, vous pouvez donc soit faire une hypothèse (par exemple, + 10%) ou l'omettre.
Cependant, l'économie n'est pas toujours l'objectif de la mise en œuvre de l'automatisation. Un exemple est vitesse d'exécution des tests(à la fois en termes de rapidité d'exécution d'un test et en termes de fréquence des tests). Pour un certain nombre de raisons, la rapidité des tests peut être critique pour une entreprise - si les investissements dans l'automatisation rapportent avec les bénéfices reçus.
Un autre exemple - exclusion du "facteur humain" du processus de test du système. Ceci est important lorsque la précision et l'exactitude de l'exécution des opérations sont essentielles pour l'entreprise. Le prix d'une telle erreur peut être beaucoup plus élevé que le coût de développement et de maintenance d'un autotest.
Pourquoi mesurer les performances ?
La mesure de l'efficacité permet de répondre aux questions : « Vaut-il la peine d'implémenter l'automatisation sur un projet ? », « Quand l'implémentation nous apportera-t-elle un résultat significatif ? », « Combien d'heures de tests manuels remplacerons-nous ? », « Est-il possible de remplacer 3 ingénieurs tests manuels par 1 ingénieur tests automatisés ? et etc.
Ces calculs peuvent aider à formuler des objectifs (ou des mesures) pour l'équipe de test automatisé. Par exemple, économiser X heures par mois de tests manuels, réduisant le coût de l'équipe de test de Y unités.







Comment désactiver les publicités sur Android : supprimer les publicités contextuelles
Le Russe écope d'une peine et d'un million d'amende pour "piratage" Conséquences négatives de la loi
Identification des facteurs clés
Les critères de classification des organisations et des entrepreneurs individuels en petites et moyennes entreprises ont changé
Voir ce qu'est la "royauté" dans d'autres dictionnaires Les pièges de la législation