Відмова від тестування часто пов'язані з критичним ставленням щодо нього з боку рекламних (особливо творчих) працівників, і навіть з економією коштів і часу. Тестування може загальмувати запуск рекламної кампанії, отже – і продукту. Разом з тим, очевидно, що при великих бюджетах тестування допомагає уникнути багатомільйонних помилок. Воно також може бути корисним і для дрібних рекламодавців, для яких нескладно підібрати прості, недорогі тести. Як кажуть класики реклами, «тестування може бути обмеженим або навіть невдалим, але воно все одно дасть щось, від чого можна відштовхуватись, чим можна керуватися».
Дослідники налічують кілька тисяч видів тестів. Не менше існує й думок про корисність та правильність проведення тих чи інших тестів.
Одне з основних питань оціночних досліджень дований: «Що власне тестувати?» Ті ж класики реклами стверджували, що «ефект реклами (за винятком реклами посилторгу) здебільшого не піддається виміру... Рекламодавці, звичайно ж, хочуть мати можливість обліку, але рекламу часто доводиться вимірювати методами скромнішими і невловимішими, ніж хотілося б. Боюся, нам доведеться примиритися з тим, що більша частина реклами зможе повністю окупити себе тільки після тривалого відрізка часу, а ступінь окупності неможливо перевірити якось точно».
Дійсно, виявити вирішальний чинник залежності між самим рекламним зверненням та його впливом (або відсутністю цього впливу) на окрему людину дуже важко. Наприклад, в ході одного з досліджень групу, що складається з керуючих по товару та керуючих службою реклами фірм, керівників робочих груп рекламних агенцій, творчих працівників, фахівців із засобів реклами та фахівців дослідницьких служб, «попросили відібрати найкращі оголошення з тих, що були вже ретельно перевірені на ринку. Результат? Хоча експертам вдалося встановити, які оголошення повинні були залучити найбільшу кількість читачів, вони не зуміли визначити, які оголошення допомогли продати. більше товару». Як говорилося раніше, крім реклами, дуже багато інших різних чинників впливає продажу. А за твердженням найавторитетніших фахівців, «методів швидкого та нескладного контролю численних факторів, що впливають на збут, не існує».
На думку Ч. Сендіджа, У. Фрайбургера і К.Ротцолла, «на реакцію впливає безліч всіляких “причин”, а кожна змінна подразника породжує безліч “ефектів”. Одне й те саме оголошення може, наприклад, дратувати, інформувати, розважати, підкріплювати впевненість, спонукати до дії, може бути повністю проігнорованим у момент контакту, а пізніше його можуть швидко забути або частково пригадати, воно може стати причиною зміни щодо або обізнаності. Тому цілком ясно, що, вирішуючи, якими параметрами реакції у відповідь скористатися, дослідник повинен багато в чому керуватися здоровим глуздом».
У зв'язку з вищесказаним видається очевидним, що оголошення (перш ніж на нього відреагують) має бути побачено. Після контакту з рекламою людина також повинна знати торгову марку або назву компанії, розумітися на властивостях, перевагах і вигодах товару. Людина може виникнути раціональна чи емоційна схильність до купівлі певного товару. До цього можна додати думку керівництва одного з найбільших світових рекламодавців General Motors: «Ефективність насамперед вимірюватиметься достовірністю, здатністю використовувати емоції та переконливістю реклами»
Тестування можна піддавати саме певні людські реакції. У цьому оцінці слід піддавати чи одиночні параметри, чи мінімальний набір, оскільки спроби аналізувати відразу дуже багато діючих параметрів реклами можуть сплутати результати. Разом з тим чим більше в цілому параметрів буде протестовано, тим точніше буде кінцевий результат. «При ретельному аналізі всього одного-двох периферійних аспектів ефективності реклами результати її тестування можуть здатися надто стерильними та нереальними для тих, хто має користуватися ними у процесі прийняття рішень. Якщо він некритично поставить знак рівності між ступенем запам'ятовуваності та впливом або зміною відносин і збутом, у нього залишається можливість покластися на віру, яка не дає жодних гарантій».
Отже, перевірки ефективності завершеної чи майже завершеної реклами проводяться різні оціночні дослідження чи тести. Вони дозволяють заощадити кошти з допомогою коригування реклами доти, як будуть профінансовані кошти її поширення. Таким чином, тестування допомагає уникнути багатомільйонних помилок. Також оцінні дослідження можуть бути корисні і після розміщення реклами, наприклад, при оцінці процесів впливу реклами на поточні продажі.
Проте з погляду практиків в повному обсязі дослідження не завжди мають цінність. Іноді вони можуть не лише допомагати, а й шкодити роботі. Інтуїція практиків може бути точнішим інструментом, ніж наукові дослідження. Тести та його результати – це рішення, вони лише надають практикам інформацію, використання якої, разом із емпіричним досвідом рекламного працівника, дає можливість приймати виважені рішення.
У цьому розділі були розглянуті різні видитестів, що застосовуються в рекламі, різні методитестування, критерії тестування та етапи тестування. Були розглянуті також особливості тестування реклами в різних ЗМІ, для чого часто використовуються різні підходи.
Особливу увагу було приділено попередньому т стиванню (претестування), оскільки воно підвищує ймовірність підготовки найефективніших текстів доти, як будуть витрачені гроші розміщення реклами.
Інший тип тестування – посттестування (або заключне тестування), зі свого боку, не має головного недоліку, властивого попередньому тестуванню – певної частки штучності. При заключному тестуванні поведінка людей не спотворюється, вона природно, реалістично. Під час заключного тестування враховується низка факторів, що також серйозно впливають на результати. Насамперед, це специфіка засобів поширення реклами, час розміщення реклами, частота її пред'явлення споживачам тощо.
Якщо все рекламне повідомлення, зазвичай, тестують на здатність стимулювати продажу, на переконливість, впізнаваність і запам'ятовуваність продукту чи марки, то рекламний текст зазвичай тестують лише переконливість. У таких тестах увага звертається насамперед на розуміння заголовка, слогана, коди, ключових слів.
Сьогодні ми отримуємо нові інструменти для тестування. Наприклад, заголовки, ключові словаможна успішно тестувати з допомогою системи контекстної реклами.
Кожен оцінний метод має специфічне поєднання переваг і недоліків, а також різну вартість. Важливим та дуже простим, а головне, дешевим засобом перевірки ефективності рекламних текстів є чек-листи (контрольні списки питань).
Відеоверсія лекції " Тестування ефективності сучасної реклами"
(Готується до публікації)
Більш детальну інформацію на цю тему можна знайти у книзі А. Назайкіна
Мета оцінки ефективності, яку деякі вже назвали «формулою нещастя» – зробити тестувальника щасливим, щоб можна було цифрами показати, що один працює добре, і його треба погладити за це по голові, а інший поганий – і його треба пороти… Оцінка тільки за цим критерієм не може бути єдиною, тому має розглядатись у сукупності з іншими показниками, такими як виконання плану, автоматизація тестування тощо.
Ефективність роботи тестувальника, як будь-якого іншого співробітника, має бути оцінена кількісно, тобто. у вимірних показниках. Але які саме показники вибрати?
Перше, що спадає на думку, – за кількістю знайдених дефектів. І саме цей показник я одразу намагався ввести в Інреко ЛАН. Проте відразу виникла бурхлива дискусія, яка й підштовхнула мене до аналізу даного критерію. На цю тему я хочу поміркувати в цій статті.
Кількість знайдених дефектів – вкрай слизький показник. Про це твердять і всі ресурси в мережі, що обговорюють цю проблему (http://www.software-testing.ru/, blogs.msdn.com/imtesty, it4business.ru, sqadotby.blogspot.com, blogs.msdn.com /larryosterman, sql.ru, http://www.testingperspective.com/ і багато інших). Проаналізувавши власний досвід та ці ресурси, я прийшов до наступного дерева проблем:
По-перше, дефект дефекту - ворожнеча. Один тестувальник може шукати дефекти у розташуванні кнопочок у додатку, інший – копатися у логіці та вигадувати складні тестові ситуації. У більшості випадків перший тестувальник знайде більше дефектів, тому що навіть на підготовку тесту у нього йтиме набагато менше часу, але цінність таких дефектів значно нижча. Ця проблема легко вирішується запровадженням критичності дефекту. Можна оцінювати за кількістю знайдених дефектів у кожній категорії. У нас, наприклад, їх 4: критичний, значний, середній та малозначний. Але оскільки межа визначення критичності не зовсім чітка, хоча в нас і є формальні ознаки критичності, можна піти двома більш надійними шляхами. Перший - певна частина знайдених дефектів за виділений період має бути не малокритичними дефектами. Другий – не враховувати в оцінці малозначні дефекти. Таким чином, ми боремося з бажанням тестувальника набрати якомога більшу кількість дефектів за рахунок опису дріб'язків, змушуючи його (або частіше її) копати глибше і знаходити серйозні дефекти. А вони завжди є, повірте моєму досвіду. Я вибрав другий варіант – відкидати незначні дефекти.
Друга причина "слизькості" такого критерію - наявність у системі достатньої кількості дефектів, щоб тестувальник міг їх знайти. Тут є три фактори. Перший – складність логіки та технології системи. Другий – якість кодування. І третій – стадія проекту. Розберемо по порядку ці три фактори. Складність логіки та технології, на якій написана система, впливає на потенційні недоліки, які можуть бути допущені. Причому залежність тут далеко ще не пряма. Якщо реалізовувати просту логіку на складній чи незнайомій платформі, то помилки будуть пов'язані з некоректним використанням технології реалізації. Якщо реалізовувати складну логіку на примітивній платформі, то, швидше за все, помилки будуть пов'язані як із самою логікою, так і зі складністю реалізації такої логіки примітивною мовою. Тобто потрібен баланс під час виборів технології реалізації системи. Але часто технологію диктує замовник чи ринок, тож вплинути ми навряд чи можемо. Отже, залишається лише враховувати цей чинник як коефіцієнт потенційної кількості дефектів. Причому значення цього коефіцієнта, швидше за все, слід визначати експертним шляхом.
Якість кодування. Тут ми вже точно ніяк не можемо вплинути на розробника. Зате ми можемо: а) знову ж таки експертно оцінити рівень розробника і включити його як ще один коефіцієнт і б) постаратися запобігти появі помилок у коді за рахунок модульних тестів, зробивши обов'язковою вимогою 100% покриття коду модульними випробуваннями.
Стадія проекту. Давно відомо, що знайти всі дефекти неможливо, хіба що для тривіальної програми чи випадково, оскільки досконалості немає межі, а будь-яка розбіжність із досконалістю можна вважати дефектом. Але одна річ, коли проект перебуває в активній стадії розробки, і зовсім інша – коли у фазі підтримки. А якщо ще врахувати фактори складності системи та технології та якості кодування, то зрозуміло, що все це докорінно впливає на кількість дефектів, які тестувальник здатний знайти. З наближенням проекту до завершення або до фази підтримки (називаємо це все умовно і визначаємо зараз інтуїтивно) кількість дефектів у системі зменшується, а значить і кількість дефектів, що знаходяться, теж. І тут потрібно визначити момент, коли вимагати з тестувальника знаходження певної кількості дефектів стає нерозумно. Для визначення такого моменту було б непогано знати, яку частину дефектів від загальної кількості ми здатні знайти і скільки дефектів ще залишилося в системі. Це тема для окремої дискусії, але можна застосувати простий і ефективний статистичний метод.
На підставі статистики попередніх проектів можна зрозуміти з певною похибкою, скільки дефектів було в системі та скільки було знайдено командою тестування у різні періоди проекту. Таким чином, можна отримати певний середньостатистичний показник ефективності команди тестування. Його можна декомпозувати по кожному окремому тестувальнику та отримати персональну оцінку. Чим більше досвіду та статистики, тим меншою буде похибка. Також можна використовувати метод «підсіву помилок», коли ми точно знаємо, скільки помилок у системі. Природно, що треба враховувати додаткові чинники, такі як тип системи, складність логіки, платформу тощо. Так, ми отримуємо залежність між фазою проекту та відсотком наявних дефектів. Тепер можна застосувати цю залежність у зворотний бік: знаючи кількість знайдених дефектів та поточну фазу проекту, ми можемо визначити загальну кількість дефектів у нашій системі (з деякою похибкою, звичайно). І далі на підставі показників персональної або загальної оцінки можна визначити, скільки дефектів тестувальник або команда здатні знайти за період часу, що залишився. Відштовхуючись від цієї оцінки, можна визначати критерій ефективності роботи тестувальника.
Функція показника ефективності роботи тестувальника може виглядати так:
Defects– кількість наявних дефектів,
Severity- Критичність наявних дефектів,
Complexity- Складність логіки системи,
Platform- платформа реалізації системи,
Phase- фаза проекту,
Period- Розглянутий період часу.
А ось вже конкретний критерій, якому має відповідати тестувальник, потрібно підбирати емпірично та з урахуванням специфіки конкретної організації.
Врахувати всі фактори наразі не вдається, однак спільно з нашим провідним розробником Іваном Астаф'євим та керівником проектів Іриною Табор, ми дійшли наступної формули, яка враховує кількість дефектів та їх критичність:
 , де
, де
E- Ефективність, що визначається за кількістю знайдених дефектів,
D Замовник– число дефектів, знайдених замовником, але які повинен був знайти тестувальник, що оцінюється,
D Тестувальник- Число дефектів, знайдених тестувальником,
kі d- Поправочні коефіцієнти на загальну кількість дефектів.
Відразу хочу відзначити, що при оцінці за цією формулою потрібно брати до уваги лише ті дефекти, які відносяться до галузі відповідальності оцінюваного тестувальника. Якщо кілька тестувальників поділяють відповідальність за пропущений дефект, цей дефект повинен бути врахований при оцінці кожного тестувальника. Також під час розрахунку не враховуються малокритичні дефекти.
 Таким чином, ми маємо параболу третього ступеня, що відображає критерій інтенсивності знаходження дефектів, якому має відповідати тестувальник. В загальному випадку, якщо оцінка тестувальника лежить вище параболи, це означає, що він працює краще за очікування, якщо нижче, то, відповідно, гірше.
Таким чином, ми маємо параболу третього ступеня, що відображає критерій інтенсивності знаходження дефектів, якому має відповідати тестувальник. В загальному випадку, якщо оцінка тестувальника лежить вище параболи, це означає, що він працює краще за очікування, якщо нижче, то, відповідно, гірше.
Тут є нюанс, пов'язаний із загальною кількістю дефектів, що аналізуються. Звичайно, чим більше статистики, тим краще, але іноді потрібно проаналізувати різні етапи проекту, іноді просто потрібна оцінка по кожному періоду часу. І одна справа, коли за період знайдено 4 дефекти та 2 з них – замовником, і зовсім інше, коли знайдено 100 дефектів, та 50 з них – замовником. В обох випадках відношення числа дефектів, знайдених замовником і тестувальником, виявиться рівним 0.5, але ми розуміємо, що в першому випадку не все так погано, а в другому час бити на сполох.
Без особливого успіху спробувавши зробити строгу математичну прив'язку до загальної кількості дефектів, ми приробили, за словами тієї ж Ірини Табір, «милиці» до цієї формули у вигляді інтервалів, для кожного з яких визначили свої коефіцієнти. Інтервалу вийшло три: для статистики від 1 до 20 дефектів, від 21 до 60 дефектів та для статистики за більш ніж 60 дефектами.
|
Кількість дефектів |
k |
d |
Припустима частина дефектів, знайдених замовником від загальної кількості знайдених дефектів |
Останній стовпець у таблиці введено пояснення того, скільки дефектів можна знайти замовнику у цій вибірці. Відповідно, що менше вибірка, то більше вписувалося може бути похибка, і більше дефектів може бути знайдено замовником. З погляду функції це означає граничне мінімальне значення відношення числа дефектів, знайдених замовником та тестувальником, після якого ефективність стає негативною, або точку перетину графіком осі X. що менше вибірка, то правіше має бути перетин з віссю. В управлінському плані це означає, що чим менша вибірка, тим менш точною є така оцінка, тому виходимо з принципу, що на меншій вибірці потрібно менш суворо оцінювати тестувальників.
Маємо графіки наступного виду:

Чорний графік відображає критерій для вибірки понад 60 дефектів, жовтий – для 21-60 дефектів, зелений – для вибірки не більше 20 дефектів. Видно, що чим більша вибірка, тим лівіше графік перетинає вісь X. Як уже говорилося, для оцінюючого співробітника це означає, що чим більша вибірка, тим більше можна довіряти цій цифрі.
Метод оцінки полягає у обчисленні ефективності роботи тестувальника за формулою (2) з урахуванням поправочних коефіцієнтів та порівняння цієї оцінки з необхідним значенням на графіку. Якщо оцінка вище графіка – тестувальник відповідає очікуванням, якщо нижче – тестувальник працює нижче за потрібну «планку». Також хочу відзначити, що всі ці цифри були підібрані емпірично, і для кожної організації вони можуть бути змінені та підібрані з часом більш точно. Тому будь-які коментарі (тут або в моєму особистому блозі) та доопрацювання я лише вітаю.
Такий метод оцінки щодо кількості знайдених дефектів командою тестування та замовником/користувачем/клієнтом, мені здається розумним і більш-менш об'єктивним. Правда, таку оцінку можна провести тільки після завершення проекту або, як мінімум, за наявності активних зовнішніх користувачів системи. Але що робити, якщо продукт не використовується? Як у цьому випадку оцінювати роботу тестувальника?
Крім того, така методика оцінки ефективності тестувальника породжує кілька додаткових проблем:
1.Один дефект починає ділитися на кілька дрібніших.
· Керівник тестування, який помітив таку ситуацію, повинен припиняти її вже неформальними методами.
2.Управління дефектами стає більш складним через збільшення кількості дублюючих записів.
· Правила фіксування дефектів у систему відстеження помилок, які включають обов'язковий перегляд наявності подібних дефектів, можуть допомогти вирішити цю проблему.
3.Відсутність оцінки якості дефектів, що є, оскільки єдиною метою тестувальника стає кількість дефектів, і, як наслідок, відсутність мотивації у тестувальника до пошуку “якісних” дефектів. Все-таки не можна прирівнювати критичність і "якість" дефекту, друге є менш поняттям, що формалізується.
· Тут вирішальну роль повинен зіграти "настрій" і тестувальника та керівника. Тільки загальне правильне (!) розуміння значення такої кількісної оцінки може вирішити цю проблему.
Резюмуючи все вищесказане, ми приходимо до висновку, що оцінювати роботу тестувальника тільки за кількістю дефектів, що перебувають, не тільки складно, але і не зовсім правильно. Тому кількість наявних дефектів має бути лише одним із показників інтегральної оцінкироботи тестувальника, причому над чистому вигляді, і з урахуванням перелічених мною чинників.
В. В. Одинцова
Користуючись численними психодіагностичними методиками, ми рідко замислюємося якість цих робочих інструментів. І даремно. Адже будь-якому практикуючому психологу відомо, що жодне психологічне обстеження неможливе без хорошого діагностичного інструментарію.
При цьому популярні збірники психологічних тестів, які публікуються останнім часом, на жаль, не можуть задовольнити вимогам справжнього професіонала, який повинен бути впевнений у діагностичних можливостях того інструменту, який він використовує у своїй роботі. Тому, проблема пошуку грамотно розробленої та надійної діагностичної методики залишається актуальною.
Основним завданням HR-Лабораторії Human Technologies є розробка якісної продукції. Однією з умов створення такої продукції є періодичні перевірки тестових методик щодо їх відповідності ряду психометричних вимог (валідності, надійності, репрезентативності, достовірності). Для цього після набору достатньої кількості протоколів проводиться статистичний аналіз тестових методик.
Розглянемо психометричний аналіз (загальна вибірка якого становила 660 людина).
Даний тест, розроблений у 90-ті рр., призначений для експрес-діагностики рівня виразності п'яти так званих "великих" факторів темпераменту та характеру та використовується для дослідження особистості дорослих людей з метою профвідбору, профконсультації, визначення напрямків психологічної допомоги, комплектування груп, самопізнання і т.п.
Основою універсальності "Великої п'ятірки факторів" є їхня крос-ситуаційність: фактори глобальної функціонально-діяльнісної оцінки людини застосовні практично до будь-якої ситуації соціальної поведінки та предметної діяльності, в яких виявляються стійкі відмінності між людьми.
Опитувальник включає 75 пунктів по три варіанти відповіді у кожному.
ШКАЛИтести є точним відтворенням факторів "Великої П'ятірки" в їх міжнародному варіанті (за винятком п'ятого фактора, який у ряді західних версій B5 позначається як "відкритість новому досвіду - обмежений практицизм"):
- екстраверсія - інтроверсія
- згода - незалежність
- організованість – імпульсивність
- емоційна стабільність – тривожність
- навченість - інертність
1. Перевірка валідності
При перевірці існуючих шкал традиційним способом – шляхом розрахунку кореляцій між відповідями на запитання та сумарним балом за шкалою – ми з'ясували, що практично всі пункти значуще корелюють зі "своїми" шкалами із середнім коефіцієнтом кореляції рівним 0,35.
Під час перевірки змістовною валідності тесту були проаналізовані формулювання завдань тесту, що змістовно відображають відповідну предметну область (область поведінки) та мають значну (позитивну або негативну) кореляцію з сумарним балом:
| Шкала | Приклад завдань тесту | Коефіцієнт кореляції |
| Екстраверсія | Для мене важливо висловити свою думку оточуючим | (0,31) |
| Я люблю брати участь у різноманітних конкурсах, змаганнях тощо. | (0,41) | |
| Мені подобається ходити в гості та знайомитися з новими людьми | (0,5) | |
| ЗГОДА | Більшості людей не можна довіряти | (-0,23) |
| Мої інтереси для мене понад усе | (-0,22) | |
| "Хто людям допомагає, той витрачає час даремно, добрими справами прославитися не можна" | (-0,3) | |
| "Кожен - сам за себе" - ось принцип, який не підведе | (-0,4) | |
| САМОКОНТРОЛЬ | Коли я лягаю спати, то вже напевно знаю, що робитиму завтра | (0,37) |
| Взявши книгу, я завжди ставлю її на місце | (0,35) | |
| Перед відповідальними справами я завжди складаю план їх виконання | (0,37) | |
| СТАБІЛЬНІСТЬ | Я легко червонію | (-0,28) |
| Якщо я вловив(а) виникнення небажаної ситуації на роботі, то це завжди викликає у мене тяжкий сумнів доти, доки ситуація не проясниться | (-0,3) | |
| Наприкінці дня я зазвичай втомлююся настільки, що будь-яка дрібниця починає виводити з себе | (-0,32) | |
| Зіпсувати мені настрій дуже просто | (-0,42) |
Аналіз наведених формулювань говорить про досить високу змістовну валідність тесту.
2. Перевірка надійності
Надійність тесту як засобу вимірювання визначається низькою ймовірністю помилок вимірювання тестових балів і тим, якою мірою результати вимірювань відтворюються при багаторазовому використанні тесту по відношенню до цієї групи піддослідних. Щоб оцінити внесок різних джерел у помилку виміру, необхідно використовувати різні способи оцінки надійності. Особливий інтерес становить оцінка внутрішньої узгодженості тесту, вона обумовлює ту частину помилки, що з відбором завдань.
Оцінка внутрішньої узгодженості тесту проводилася у вигляді розрахунку альфа-коэффициента Кронбаха. Даний коефіцієнт є оцінкою надійності, що базується на гомогенності шкали або сумі кореляцій між відповідями піддослідних на питання всередині однієї і тієї ж тестової форми.
У нашому випадку розрахований для кожної шкали альфа-коефіцієнт надійності Кронбаха показав загалом пристойний рівень внутрішньої узгодженості, традиційний для особистісних експрес-опитувальників, у яких субшкали містять обмежену кількість пунктів (менше 20):
Нагадаємо, що суворим психометричним вимогам, що висуваються до ефективно працюючого особистісного тесту, відповідає значення альфа-коефіцієнтів вище 0,8.
У нашому випадку відносно низький рівень значення коефіцієнтів надійності Кронбаха можна пояснити змістовною об'ємністю даних шкал: на кожну шкалу припадає по 15 різнопланових питань, що дозволяє розширити область охоплення досліджуваних факторів, жертвуючи разом з тим. високим рівнемвнутрішньої узгодженості.
Особливо гостро це позначилося на факторних шкалах "Угода" і "навчання", за якою альфа-коефіцієнт виявився нижче 0,6.
3. Перевірка репрезентативності
При переході від вибірки стандартизації (рис.1 - 300 людина) до вибірці популяції (рис.2 - 660 людина) проявляється стійкість зміни розподілу тестових балів, що свідчить про репрезентативності тестової методики:
Рис.1.Вибір стандартизації (300 осіб)

Рис.2.Вибірка популяції (660 осіб)
Крім візуальної схожості цих розподілів, використаний нами статистичний хі-квадрат критерій Пірсона показав такий ступінь подібності розподілів:
Дані значення хі-квадрату потрапляють у проміжок невизначеності: коли не можна однозначно прийняти або однозначно відкинути гіпотезу щодо узгодженості розподілів.
Такий результат може бути обумовлений основною властивістю експрес-тесту, а саме малою кількістю питань, що працюють на кожну шкалу. З огляду на цей факт результати перевірки репрезентативності можна визнати задовільними.
4. Перевірка достовірності
Оскільки випробувані, які проходили тестування на сайті, перебували у ситуації клієнта (були зацікавлені у достовірних результатах), то з ймовірністю отримані результати вважатимуться достовірними.
Проте в ситуації експертизи (коли в результатах тестування зацікавлена третя особа) дані можуть спотворюватися від втручання свідомих фальсифікацій (брехні, нещирості випробуваного) або несвідомих мотиваційних факторів. Щоб уникнути цього до версії, призначеної для подібних випадків (B5splus), була додана шкала брехні (в даний момент ця версія проходить апробацію на нашому сайті).
Отримані результати є свідченням високої якості та ефективності методики, що важливо, адже професійний рівень спеціаліста часто визначається тим інструментом, яким він користується.
Проте слід пам'ятати, що навіть потужний сучасний інструмент не гарантує повної відсутності помилок. Щоб уникнути їх, мало мати комп'ютер і тестову програму щодо нього. Обов'язково потрібний ще й досвідчений психолог, який контролює виконання тесту. Отже наявність тестів, що пройшли серйозну психометричну адаптацію, зовсім не скасовує професіоналізму та досвіду психолога, покликаного перевіряти правдоподібність тестових результатів з використанням паралельних джерел інформації (включаючи власне спостереження, бесіду тощо).
Тестування програмного забезпечення- це оцінка програмного забезпечення/продукту, що розробляється, щоб перевірити його можливості, здібності та відповідність очікуваним результатам. Існують різні типи методів, що використовуються в галузі тестування та забезпечення якості про них і йтиметься у цій статті.
Тестування програмного забезпечення є невід'ємною частиною циклу програмного забезпечення.
Що таке програмне забезпечення?
Тестування програмного забезпечення - це не що інше, як випробування шматка коду до контрольованих та неконтрольованих умов експлуатації, спостереження за виходом, а потім вивчення, чи відповідає він попередньо визначеним умовам.
Різні набори тест-кейсів та стратегій тестування спрямовані на досягнення однієї загальної мети - усунення багів та помилок у коді, та забезпечення точної та оптимальної продуктивності програмного забезпечення.
Методика тестування
Широко використовуваними методами тестування є модульне тестування, інтеграційне тестування, приймальне тестування та тестування системи. Програмне забезпечення піддається цим випробуванням у порядку.
3) Системне тестування
4) Приймальні випробування
Насамперед проводиться модульний тест. Як підказує назва це метод випробування на об'єктному рівні. Окремі програмні компоненти тестуються на помилки. Для цього тесту потрібне точне знання програми та кожного встановленого модуля. Отже, ця перевірка здійснюється програмістами, а чи не тестерами. Для цього створюються тест-коди, які перевіряють, чи поводиться програмне забезпечення так, як замислювалося.

Окремі модулі, які вже були піддані модульному тестуванню, інтегруються один з одним і перевіряються на наявність несправностей. Такий тип тестування насамперед виявляє помилки інтерфейсу. Інтеграційне тестування можна здійснювати за допомогою підходу "зверху вниз", дотримуючись архітектурної споруди системи. Іншим підходом є підхід знизу вгору, який здійснюється з нижньої частини потоку управління.
Системне тестування
У цьому тестуванні вся система перевіряється на наявність помилок і багів. Цей тест здійснюється шляхом сполучення апаратних та програмних компонентів усієї системи, а потім виконується її перевірка. Це тестування числиться під методом тестування "чорної скриньки", де перевіряються очікувані для користувача умови роботи програмного забезпечення.
Приймальні випробування
Це останній тест, який проходить перед передачею програмного забезпечення клієнту. Він проводиться, щоб гарантувати, що програмне забезпечення, яке було розроблено відповідає всім вимогам замовника. Існує два типи приймально-здавальних випробувань - те, що здійснюється членами команди розробників, відомо як внутрішнє приймальне тестування (Альфа-тестування), а інше, яке проводиться замовником, відомо, як зовнішнє приймальне тестування.
Якщо тестування проводиться за допомогою ймовірних клієнтів, воно називається приймальними випробуваннями клієнта. Якщо тестування проводиться кінцевим користувачем програмного забезпечення, воно відомо, як приймальне тестування (бета-тестування).
Існує кілька основних методів тестування, які формують частину режиму тестування програмного забезпечення. Ці тести зазвичай вважаються самодостатніми у пошуку помилок та багів у всій системі.

Тестування методом чорної скриньки
Тестування методом чорної скриньки здійснюється без будь-яких знань внутрішньої роботи системи. Тестер буде стимулювати програмне забезпечення для користувача середовища, надаючи різні входи і тестуючи згенеровані виходи. Цей тест також відомий як Black-box, closed-box тестування чи функціональне тестування.
Тестування методом білої скриньки
Тестування методом " Білої скриньки", на відміну від "чорної скриньки", враховує внутрішнє функціонування та логіку роботи коду. Для виконання цього тесту, тестер повинен мати знання коду, щоб дізнатися точну частину коду, що має помилки. Цей тест також відомий як White-box, Open-Box або Glass box тестування.
Тестування методом сірої скриньки
Тестування методом сірої скриньки або Gray box тестування, це щось середнє між White Box і Black Box тестуванням, де тестер має лише загальні знання даного продукту, необхідні для виконання тесту. Ця перевірка здійснюється за допомогою документації та схеми інформаційних потоків. Тестування проводиться кінцевим користувачем або користувачам, які представляються як кінцеві.
Нефункціональні тести

Безпека програми є одним із головних завдань розробника. Тестування безпеки перевіряє програмне забезпечення на забезпечення конфіденційності, цілісності, автентифікації, доступності та безвідмовності. Індивідуальні випробування проводяться з метою запобігання несанкціонованому доступу до програмного коду.

Стрес-тестування є методом, при якому програмне забезпечення піддається впливу умов, що виходять за межі нормальних умов роботи програмного забезпечення. Після досягнення критичної точки отримані результати записуються. Цей тест визначає стійкість усієї системи.

Програмне забезпечення перевіряється на сумісність із зовнішніми інтерфейсами, такими як Операційні системи, апаратні платформи, веб-браузери та ін. Тест на сумісність перевіряє, чи сумісний продукт із будь-якою програмною платформою.

Як підказує назва, ця методика тестування перевіряє обсяг коду чи ресурсів, що використовуються програмою під час однієї операції.

Це тестування перевіряє аспект зручності та практичності програмного забезпечення для користувачів. Легкість, з якою користувач може отримати доступ до пристрою, формує основну точку тестування. Юзабіліті-тестування охоплює п'ять аспектів тестування, - навчання, ефективність, задоволеність, запам'ятовування та помилки.
Тести у процесі розробки програмного забезпечення

Каскадна модель використовує підхід "зверху-вниз", незалежно від того, чи використовується вона для розробки програмного забезпечення або для тестування.
Основними кроками, що беруть участь у даній методиці тестування програмного забезпечення, є:
- Аналіз потреб
- Тест дизайну
- Тест реалізації
- Тестування, налагодження та перевірка коду або продукту
- Впровадження та обслуговування
У цій методиці ви переходите до наступного кроку тільки після того, як ви завершили попередній. У моделі використовується не-ітераційний підхід. Основною перевагою даної методики є її спрощений, систематичний та ортодоксальний підхід. Тим не менш, вона має багато недоліків, так як баги та помилки в коді не будуть виявлені до етапу тестування. Найчастіше це може призвести до втрати часу, грошей та інших цінних ресурсів.
Agile Model
Ця методика заснована на виборчому поєднанні послідовного та ітеративного підходу, на додаток до досить великого розмаїття нових методів розвитку. Швидкий та поступальний розвиток є одним із ключових принципів цієї методології. Акцент робиться на отримання швидких, практичних та видимих виходів. Безперервна взаємодія з клієнтами та участь є невід'ємною частиною всього процесу розробки.
Rapid Application Development (RAD). Методологія швидкої розробки додатків
Назва говорить сама за себе. І тут методологія приймає стрімкий еволюційний підхід, використовуючи принцип компонентної конструкції. Після розуміння різних вимог даного проекту, готується швидкий прототип, а потім порівнюється з очікуваним набором вихідних умов та стандартів. Необхідні зміни та модифікації вносяться після спільного обговорення із замовником або групою розробників (у контексті тестування програмного забезпечення).
Хоча цей підхід має свою частку переваг, він може бути невідповідним, якщо проект великий, складний або має надзвичайно динамічний характер, в якому вимоги постійно змінюються.
Спіральна модель
Як видно з назви, спіральна модель заснована на підході, в якому є цілий ряд циклів (або спіралей) з усіх послідовних кроків каскадної моделі. Після того, як початковий цикл буде завершено, виконується ретельний аналіз та огляд досягнутого продукту або виходу. Якщо вихід не відповідає вказаним вимогам або очікуваним стандартам, проводиться другий цикл тощо.
Rational Unified Process (RUP). Раціональний уніфікований процес
Методика RUP також схожа на спіральну модель, тому вся процедура тестування розбивається на кілька циклів. Кожен цикл складається з чотирьох етапів - створення, розробка, будівництво та перехід. Наприкінці кожного циклу продукт/вихід переглядається, і далі цикл (що складається з тих самих чотирьох фаз) слід у разі потреби.
Застосування інформаційні технологіїзростає з кожним днем, також важливість правильного тестування програмного забезпечення зросла в рази. Багато фірм містять для цього штат спеціальних команд, можливості яких перебувають на рівні розробників.
Переклад: Ольга Аліфанова
У забезпеченні якості розрізняють верифікацію та валідацію. Верифікація відповідає питанням, чи правильно ми створюємо продукт, а валідація – питанням, чи ми взагалі створюємо, що потрібно. Деякі люди проводять вододіл між забезпеченням якості та тестуванням, виходячи саме з цих визначень.
На мою думку, використання термінів "верифікація" і "валідація" може призвести до помилкових дихотомій. Для мене тестування – це діяльність, пов'язана з дизайном, і тому покриває досить широку область. Я вірю, що тести можуть стати якоюсь "спільною мовою". Я вірю, що тести можуть безпосередньо кодувати специфікації та вимоги. І я вірю, що тести – це джерело знань про область чи продукт. Занадто великий наголос на різницю між верифікацією та валідацією – це неефективний та нерезультативний спосіб зрозуміти, як саме тестування доповнює забезпечення якості.
На мою думку, нездатність сприймати тестування та забезпечення якості, як два різні, що доповнюють один одного процесу – це сприйняття, якому явно не вистачає деякої витонченості.
Насправді я згоден, що різницю між верифікацією та валідацією цілком виправдані. Зрештою ефективність – це здатність робити щось правильно. Результативність, з іншого боку, - це здатність видавати правильний результат. Ефективність сфокусована на процесі та націлена на доведення його до кінця, а результативність – на продукті (тобто, власне, на результаті цього процесу). Можна сказати й так: ефективність концентрується насамперед у тому, щоб уникнути помилок, а результативність – успіху незалежно від кількості промахів, допущених шляхом.
Проте мені здається, що є спосіб розрізняти ефективність та результативність, який набагато кращий за розуміння різниці між верифікацією та валідацією. Адже тестування прямо-таки вимагає гнучкості та інновацій.
І це саме та точка, у якій виникає цікавий парадокс. Для постійної, безперервної підтримки ефективності вам потрібний пристойний рівень дисципліни та твердості. Проте саме дисципліна та стійкість до змін позбавляють процеси гнучкості! Якщо ви робите те саме однаково раз за разом, вас ніколи не осінить нічим інноваційним.
Оскільки ефективність у цьому контексті пов'язані з верифікацією, це, що верифікація може перетворитися на статичну діяльність.
Результативність, навпаки, значно краще адаптується до змін і вимагає великої гнучкості. Для досягнення хороших результатівпотрібно заохочувати інновацію, тому що тоді люди замислюватимуться про те, що саме вони зараз роблять, і чи варто займатися саме цим у конкретному контексті та при впливі конкретних факторів. Однак ця гнучкість та адаптивність ведуть до надто великого багатства виборів та потенційної нездатності на свідомі рутинні зусилля, які можна буде відтворити і поза поточною ситуацією.
Так як ефективність у нашому контексті пов'язана з валідацією, все вищесказане означає, що валідація може стати надто динамічним видом діяльності.
І тут-то в гру має вступати витонченість рішень, що розриває це порочне коло і дає можливість оцінити свою ефективність і результативність, дивлячись на неї іншими очима. Витонченість рішень не просто відповідає на запитання, чи зробили ми щось краще, чи подумали ми про щось краще, а скоріше дає відповідь, чи стали ми краще розуміти, що відбувається, чи ми створили базу для майбутньої діяльності?
Витонченість можна розглядати у тому числі як мінімізацію складності. У світі розробки люди часто поділяють складність рішень на обов'язкову та випадкову. Отже, для того, щоб рішення у тестуванні були витонченими, вони повинні складатися тільки з "обов'язкової складності" і практично не містити випадкової. Звучить, мабуть, загадково? Так, можливо, оскільки скільки людей – стільки думок про те, де починається "складність". Для мене складність рішень у тестуванні виникає, коли в системі немає виборів і є висока невизначеність.
Якщо ви дозволяєте тестуванню бути інноваційним і гнучким (тобто результативним), але при цьому підтримуєте певний рівень жорсткості та дисципліни (ефективність), у вас має бути певне зведення правил щодо того, як керуватися з вибором (в сенсі, як надавати цей вибір) та невизначеністю (як її знищувати).
Не занудуватиму на цю тему, а просто наведу приклади того, про що я говорю. У своїх прикладах я хочу спробувати змусити команди тестування думати про свої тести, використовуючи терміни "ефективність", "результативність" та "витонченість". Почну з деяких аксіом (не підберу іншого слова) і постараюся зробити свої приклади якомога коротшим і зрозумілим. Є речі, в які має вірити вся команда – або, як мінімум, діяти так, ніби вона у них вірить. І перша ж моя аксіома стверджує те, про що я говорив вище!
- Тестування може виконуватися ефективно, результативно та витончено.
- Тестування потребує активних, професійних, технічних досліджень.
- Мета тестування – це виразне повідомлення потрібної інформації вчасно.
- Тестувальники в якомусь сенсі – письменники та редактори. Отже, етика витонченості та професійна гордість – неодмінні атрибути гарної, мотивованої роботи з належним рівнем уваги.
Ось кілька прикладів, що ілюструють ці положення. Для початку давайте розглянемо всі ці концепції стосовно тесту.
- Ефективнийтест повинен концентруватися на введенні, процесі, виведенні.
- Результативнийтест має бути виразним та демонструвати мету тесту.
- Ефективнийтест повинен фокусуватися на одному виразному результаті конкретної дії, а не на кількох одночасно.
- Результативнийтест групує пов'язані між собою спостереження.
- ЕфективнийТест дає конкретний приклад необхідних даних.
- Результативнийтест розповідає про Загальні умови, під які повинні потрапляти дані, що тестуються.
- Витонченийтест визначає конкретну поведінку системи та її функціональність.
Тепер давайте застосуємо ці концепції до тест-сьюту:
- Ефективнийтест-сьют визначає які дані будуть валідними, а які ні.
- Ефективнийтест-сьют перевіряє і валідні та невалідні дані.
- Результативнийтест-сьют групує типи даних у класи.
- Витонченийтест-сьют може складатися для досліджень завдань бізнесу та його процесів.
І, нарешті, давайте докладемо ці визначення до тестування як виду діяльності:
- ЕфективнеТестування використовує скрипти, що структурують дослідницький процес.
- РезультативнеТестування застосовує дослідницькі практики, які привносять у скрипти варіативність.
- ВитонченеТестування використовує скриптовані дослідницькі практики, щоб продемонструвати цінність програми для споживача шляхом вивчення того, як вона використовується.
- ЕфективнеТестування використовує сценарії, що показують, як продукт реалізує своє призначення.
- РезультативнеТестування використовує сценарії, які демонструють, що має статися, щоб користувальницька потреба була задоволена.
- Витонченетестування описує вимоги та демонструє можливості програми.
Все це важливо усвідомлювати, тому що те, що ви робите і те, як саме ви це робите - це основа того, що і як ви робитимете в майбутньому. Це також підтримує групову динаміку та роздуми про наведені вище концепції. Ось що я маю на увазі:
- Деякі тестувальники вважають за краще називати тест-кейси "умовами тесту". Деякі – навпаки. Хтось ігнорує обидва терміни. Я вважаю, що результативне тестування групує тестові умови та робить їх варіаціями тест-кейсів. Результативне тестування використовує умови тесту, задані спеціальними параметрами необхідних даних.
- Термінологія "позитивне/негативне тестування" давно вже вийшла з моди у досвідчених випробувачів. Витончене тестування концентрується на описі валідних та невалідних умов. Це означає, що тестувальники повинні ефективно та результативно тестувати, визначаючи всі умови тесту, які можуть змінюватися (що призводить, у свою чергу, до угруповання валідних та невалідних умов), а також переконатися, що вони приймають виважені рішення, вибираючи певні набори даних та ігноруючи решту.
- Витончені тести – це чемпіони ваших тестів. Якщо у вас є група тестів, які перевіряють за фактом схожі речі, а ваш час обмежений – ви встигнете прогнати лише частину з них. У таких випадках використовуйте тести, які з великою ймовірністю розкриють цілий пласт помилок. Такі тести можуть бути вкрай витонченими.
- Ефективний тест має бути ні надто простим, ні надто складним. Звичайно, можна впхнути в один кейс цілу серію перевірок, але можливі побічні ефекти такого способу створення тестів можуть замаскувати купу багів. Отже, результативні кейси повинні включати різні точки спостереження (або інший шлях до тієї ж точки спостереження), і виконуватися окремо.
- Деякі техніки тестування вкрай ефективні щодо вибору специфічних даних та організації цих даних у комбінації чи послідовності. Але витончене рішення виникне, коли тестувальники вибирають ці дані, виходячи із взаємодії різних функціональностей і потоків даних, і досліджують шляхи через інтерфейс користувача з розумінням того, як жива людина буде використовувати цю систему.
- Результативний кейс має бути здатним надати вам інформацію. Вам потрібні тести, які нададуть відповіді на запитання, які ви задали. Ціль тесту – абсолютно необов'язково пошук бага, його мета – це збір інформації. Тест цінний не тоді, коли він може знайти баг - він повинен бути здатний постачати вас інформацією (хоча ця інформація може полягати і в наявності бага, якщо з додатком щось не так). Витончене рішення завжди націлене отримання певної інформації під час тестування.
- Результативне тестування потребує розуміння вимог та їхнього зв'язку з тим, як користувачі сприймають цінність нашого продукту. Нам потрібно розуміти наших користувачів, а не просто читати специфікації та вимоги! Витончене тестування використовує евристику для структурування цього розуміння. Воно також змушує тестування розповідати захоплюючі історії про дії реальних людей.
Можливо, мені з самого початку варто було відзначити, що в мене не було мети виставити себе істиною в останній інстанції щодо відповіді на питання, яке тестування буде ефективним, результативним і витонченим. Я тільки хотів донести свою позицію: я вважаю, що команди тестування, які розуміють різницю між цими концепціями, здатні








Вимоги до якості
Ресурси торфу Фрезерний видобуток торфу
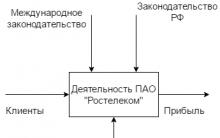
Закрите акціонерне товариство компанія транстелеком
Налаштування Wi-Fi обладнання
Царга пастеризації для відбору голів при ректифікації